Assembly avançado
Do baixo para o alto para o baixo nível
Quando estamos a programar com uma linguagem do género Assembly, é muito difícil estarmos a encontrar um erro, visto ser uma linguagem de muito baixo nível. Sendo assim, estamos muito mais propícios a errar e passar mais tempo a preocupar sobre onde é que o nosso programa está a falhar.
Assim, para começarmos a programar com esta linguagem temos que primeiro que tudo estabelecer uma correspondência com o mundo real. Começamos, evidentemente, por estabelecer uma relação com linguagens de alto nível, por isso comparamos um código em Assembly com um código em C:
Em C, nós estabelecemos variáveis fazendo
a = 2;
b = a;e o nosso compilador é que escolhe se as coloca em registos ou na memória. Contudo, não funciona da mesma forma em Assembly. Nesta linguagem temos dois processos diferentes para registos e para memória. Em termos de registos temos que fazer
MOV R1, 2
MOV R2, R1Atribuindo, desta forma, primeiro o valor de 2 a R1 (equivalente a a) e de seguida fazemos a atribuição do valor de R1 a R2 (equivalente a atribuir o valor de a a b).
Em termos de memória, teremos que fazer os seguintes comandos:
MOV R1, 2
MOV [A], R1
MOV R1, [A]
MOV [B], R1Em escrita corrente, essencialmente o que estamos a fazer é atribuir o valor de 2 a a e colocando A como o endereço da variável a. Depois, lemos a da memória para um registo e colocamos B como o endereço da variável B, obtendo o nosso .
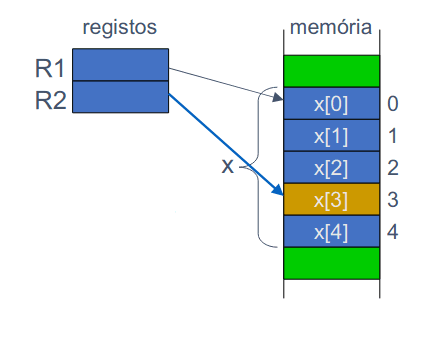
Assim, conseguimos, de forma similar, obter vetores na nossa linguagem de baixo nível. Como é sabido, podemos inicializar vetores em C da seguinte forma:
int x[5];
x[3] = x[3] + 4;Passando para Assembly, vetores, são obtidos através de:
MOV R1, X ; endereço de base de x
MOV R2, [R1+6] ; x[3]
ADD R2, 4 ; x[3] + 4
MOV [R1+6], R2 ; x[3] = x[3] + 4
Contudo, a questão coloca-se: como é que tratamos de vetores com índice variável?
MOV R1, X ; endereço de base de x
MOV R3, 0 ; inicializa índice i
L1: MOV R2, [R1+R3] ; x[i]
ADD R2, 4 ; x[i] + 4
MOV [R1+R3], R2 ; x[i] = x[i] + 4
ADD R3, 2 ; i++ (i+=2 para usar o i como índice)
MOV R4, 10 ; 5*2 (5 elementos, mas há 10 bytes)
CMP R3, R4 ; i != 5 (10 em endereço)
JNZ L1 ; volta para trás enquanto i != 5 instruções a seguir ao forInstrução if
A instrução if em qualquer linguagem de alto nível dá-nos a opção de obter mais do que um resultado diferente numa parte do nosso código, criando assim diferentes percursos que o nosso programa pode percorrer. Em Assembly também é possível criar esta instrução através do comando JZ.
Este comando funciona calculando uma expressão que afeta o bit de estado Z, se a expressão booleana for falsa, o programa não irá executar as instruções seguintes e em vez disso salta para outra porção do código, como podemos ver no exemplo seguinte:
...
JZ OUT
instruções
OUT: ...Instrução if-else
Também conseguimos, em qualquer programa, forçar a percorrer dois caminhos já predefinidos pelo programador através da instrução if-else. Esta instrução origina duas condições diferentes, que podem originar mais do que dois caminhos diferentes (ou seguem o if, ou seguem o else, ou há erro).
Como já sabemos, em C podemos implementar esta instrução através de:
if {expressão-booleana}
{instruções 1}
else
{instruções 2}Da mesma forma como já vimos acima, podemos fazer esta instrução em Assembly através das mesmas instruções utilizadas na instrução if mas com apenas mais alguns detalhes, como podemos ver abaixo.
expressão ; calcula expressão (afeta bit de estado Z)
JZ ALT ; se expressão booleana for falsa, salta
instruções 1 ; código das instruções dentro do if
JMP OUT ; não pode executar instruções 2
ALT: instruções 2 ; código das instruções da cláusula else
OUT: ... ; instrução a seguir ao ifExpressões booleanas no if
Agora que já sabemos como podemos realizar a instrução if ou if-else em Assembly, quais são as expressões que podemos utilizar nestas condições?
Uma das principais expressões que podemos usar é em termos de expressões booleanas. Isto é, fazemos comparações entre os nossos valores e vemos se cumpre ou não os nossos requisitos. O PEPE tem instruções para suportar os vários casos relacionais possíveis, por exemplo, <, <=, >, >=, =. Esta comparação entre os valores é dada pela instrução CMP, que pode ser utilizada como descrito em baixo:
CMP Ra, Rb ; afeta bit de estado N
JGE OUT ; se a>=b, bit de estado N estará a 0
; ou então: JNN OUT
instruções ; código das instruções dentro do if
OUT: ... ; instruções a seguir ao ifCiclos
Como já sabemos, é possível gerar casos diferentes em Assembly, assim, evidentemente também será possível criar ciclos dentro do nosso programa. Este ciclos são, tal como o nome indica, um bloco de código que se executa um certo número de vezes. Estes blocos de código podem ser fixos (ou incondicionais), como é o caso do for ou podem ser condicionais, como vemos no caso do while e do-while.
Para o caso de ciclos incondicionais (for), podemos representá-los em assembly da seguinte forma:
MOV R1, 0
LOOP: MOV R2, N
CMP R1, R2
JGE OUT
instruções
ADD R1, 1
JMP LOOP
OUT: ...Essencialmente, o que estamos a fazer neste ciclo é inicializar a variável de índice (i=0), de seguida vemos se i é menor que N, se i for maior ou igual, então já terminámos o nosso ciclo e saímos do nosso ciclo, se não, executamos umas instruções, incrementamos o valor de R1, e voltamos a executar o loop.
Para o caso de ciclos condicionais (while), o código em assembly é relativamente parecida, com a única diferença que não vamos fazendo comparações para ver se já chegamos ao número de iterações que pretendíamos. Assim, para executar estes ciclos, teremos que implementar as seguintes instruções:
LOOP: expressão
JZ OUT
instruções
JMP LOOP
OUT: ...Como podemos ver acima, o que estamos a fazer é ter um código para calcular a expressão, se esta for falsa então saímos do ciclo, caso contrário, percorremos o código de instruções dentro do while e voltamos a percorrer o ciclo desde o começo.
Da mesma forma, para ciclos condicionais (do-while), vamos implementar um código extremamente parecido com o de ciclos while:
LOOP: instruções
expressão
JNZ LOOP
OUT: ...A única diferença destes ciclos para os de cima é que mantemos sempre uma expressão em mente, se esta expressão for verdadeira continuamos o nosso ciclo, caso contrário passamos a instrução a seguir ao do-while.
Ter estes conhecimentos de instruções relativamente fáceis nesta linguagem de baixo nível permite-nos conseguir chegar a comandos de níveis muito superiores, nomeadamente conseguimos implementar métodos de ordenação de vetores como o Bubblesort.
Apontadores
Algo muito importante em qualquer linguagem de programação são apontadores. Estes são usados para referência a blocos de memória criados dinamicamente ou para fazer passagem de parâmetros por referência a funções. Em casos como no Bubblesort tem um custo muito menor usar apontadores!
Assim, podemos admitir que estas abstrações introduzem muitas vezes um custo ao nível de desempenho e, por esse motivo, tem que haver um compromisso entre abstrações amigáveis para o programador e eficiência da computação. O nosso compilador ideal consegue o compromisso ótimo entre estas duas variáveis, por isso é que é fundamental ter um conhecimento profundo da arquitetura dos computadores.
Rotinas
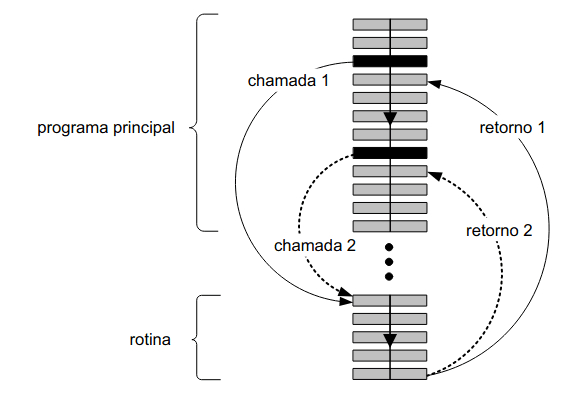
Ao programarmos em linguagens de baixo nível temos que nos focar em conceitos de extrema importância, nomeadamente rotinas. Para tal. temos que começar por nos questionar como podemos chamar ou retornar de uma rotina.
Visto que rotinas não sabem de onde são chamadas, temos que usar o par CALL-RET para podermos passar de uma parte do nosso código a uma rotina automaticamente. A pilha memoriza o endereço que está a seguir ao CALL (valor do PC), ficamos assim com:
SP <- SP - 2
M[SP] <- PC
PC <- endereço da rotinaAo retornarmos ficamos com:
PC <- M[SP]
SP <- SP + 2
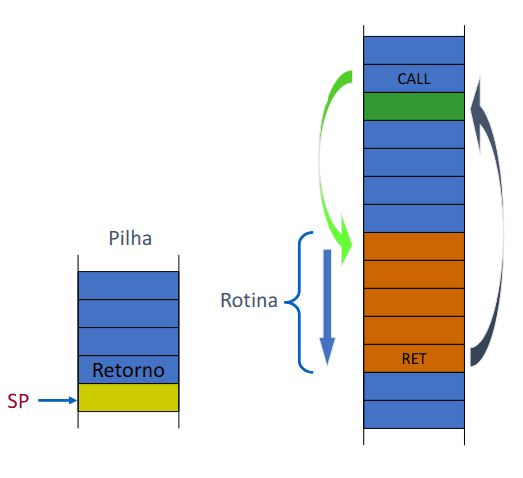
Já que já chamamos a nossa rotina, podemos agora questionar-mos-nos como é que evitamos que a rotina "estrague" os valores dos registos no programa principal? Visto que uma rotina nunca sabe aonde é que é chamada, se usamos registos temos que, primeiro, salvá-los na pilha antes de os usar, e, de seguida, restaurá-los pela ordem inversa antes de retornar ao código principal.
Antes de guardar quaisquer valores na pilha temos que ter em atenção que é necessário verificar o tamanho máximo previsível para a pilha e reservar espaço suficiente, geralmente 100H palavras é suficiente; também é necessário inicializar o SP com o endereço seguinte à área reservada para a pilha.
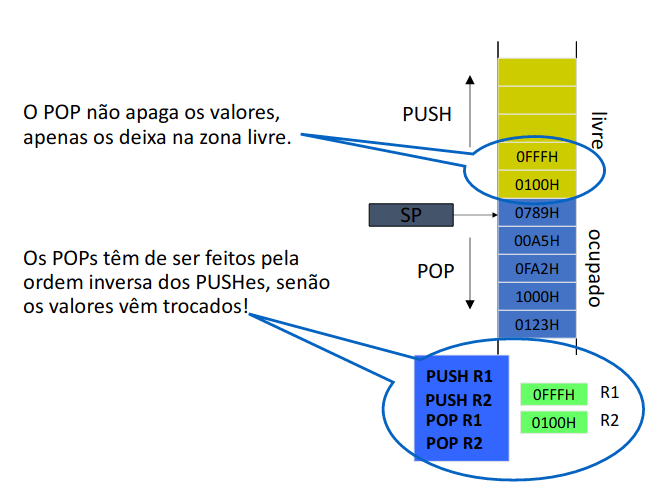
Pilha (stack)
Ao colocarmos seja o que for numa pilha, o nosso SP aponta para a última posição ocupada da pilha, ou seja no topo da pilha, isto é, fazemos:
PUSH Ri ; SP <- SP-2 , M[SP] <- Ri
POP Ri ; Ri <- m[SP] , SP <- SP + 2
Recursividade
Linguagens de baixo nível não são exceção no que toca a recursividade. Uma rotina pode-se chamar a ela própria, sendo que vai guardando o endereço de retorno e eventuais registos PUSHed. É de realçar que tem que haver uma condição de terminação que permite regressar das N instâncias da rotina, e, a profundidade da pilha pode ser atingida dependendo do caso concreto (cada chamada recursiva substitui uma iteração na versão iterativa do algoritmo).
Passagem de valores
A última questão que nos falta responder é como é que podemos passar parâmetros de uma parte da função para outra. Quando chamamos uma função temos que colocar os parâmetros num local combinado com a função, e o mesmo tem que ser feito para o valor de retorno.
Passagem de valores pela pilha
| Vantagens | Desvantagens |
|---|---|
| Genérico, dá para qualquer número de parâmetros | Pouco eficiente, muitos acessos à memória |
| Recursividade fácil, já se usa a pilha | É preciso cuidado com os PUSHes e POPs, tem de se "consumir os parâmetros e os valores de retorno |
Passagem de valores por registos
| Vantagens | Desvantagens |
|---|---|
| Eficiente, registos | Menos geral, número de registos limitado, não suporta recursividade |
| Registo de saída de uma função pode ser logo o registo de entrada noutra, não é preciso copiar o valor | Estraga registos, pode ser preciso guardá-los na pilha |
Exceções e interrupções
Uma exceção corresponde a um qualquer evento que pode ocorrer de forma inesperada para o programa que está a correr; são situações que não são práticas de se estar sempre a testar se algo tiver acontecido e nem sempre podemos saber como reagir ou tratar o evento logo que este ocorra. Para além disto a origem de uma exceção pode ser causada por vários fatores diferentes, nomeadamente pelo próprio programa (são síncronas em relação ao programa), ou pela ativação de um pino extremo (interrupções, são assíncronas face ao programa, sendo imprevisível a instrução em que ocorrem).
A solução é implementar interrupções. Ao interromper o programa normal e invocar uma rotina de tratamento da exceção.
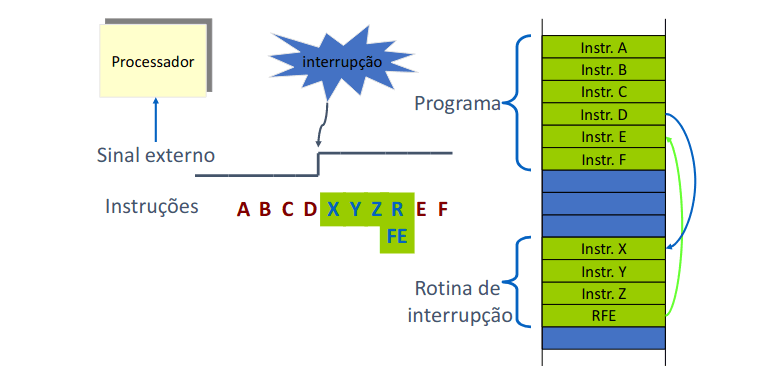
O processo tem vários pinos de interrupção que podem ligar a relógios (temporizadores), botões, sensores, etc.
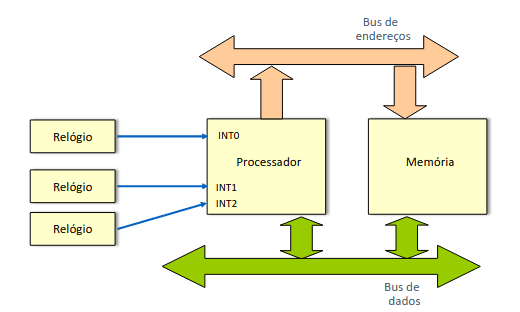
Rotinas de interrupção
As rotinas de interrupção podem ser invocadas a qualquer momento usando um sinal externo. Este sinal muda o valor do flanco (de 0 para 1, que é o caso mais comum, ou de 1 para 0) e tem um dado valor de nível que pode ser 0 ou 1. É necessário manter em mente que não podemos alterar nada do estado do processador nem mesmo os bits de estado. A invocação da rotina de interrupção guarda automaticamente na pilha, ou seja faz o equivalente a dois PUSHs, o nosso endereço de retorno, que vai ser o endereço da próxima instrução na altura em que a interrupção aconteceu, e o registo dos bits de estado.
A instrução RFE (Return From Exception) faz o equivalente a dois POPs pela ordem inversa, repondo os bits de estado e fazendo o retorno. Atenção que RET e REF NÃO SÃO equivalentes!!.
Se a rotina de interrupção alterar qualquer registo, tem de o guardar primeiro na pilha e restaurá-lo antes do RFE.
As rotinas de interrupção são, mecanismos de baixo nível que devem ser muito curtos e, por regra, não devem permitir ser interrompidas, contudo, há sempre tal possibilidade. O seu papel e essencialmente assinalar a ocorrência da interrupção desencadeando ações a executar por software de mais alto nível, e não diretamente por elas.
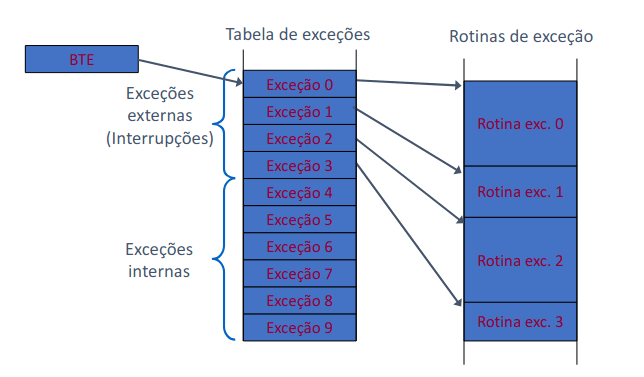
Tabela de exceções
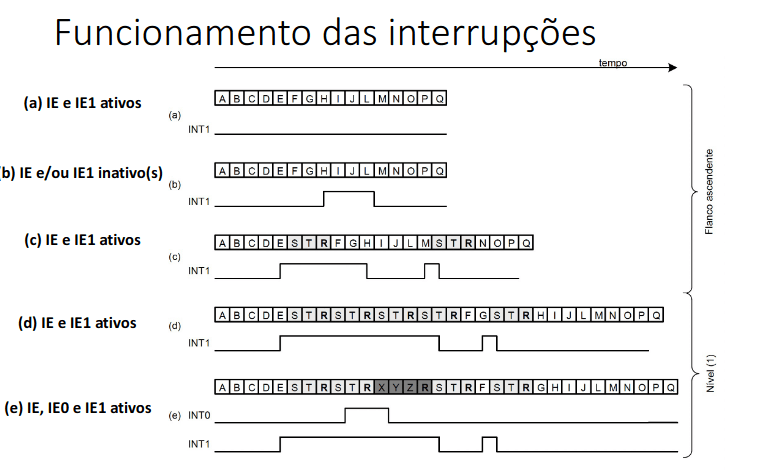
Bits de estado IE
Um programa pode estar a executar operações críticas que não devem ser interrompidas, por isso, existe um bit de estado (IE) que quando está a 0 impede o processador de atender interrupções. É fácil manipular este bit através de duas instruções:
- EI (Enable Interrupts), faz IE <- 1
- DI (Disable Interrupts), faz IE <- 0
A própria rotina de interrupção pode ser crítica e não permitir interrupções a ela própria. Por isso, IE é colocado a 0 automaticamente quando uma interrupção é atendida. O bit IE é automaticamente reposto no RFE, porque o registo das flags é reposto.
Fluxograma
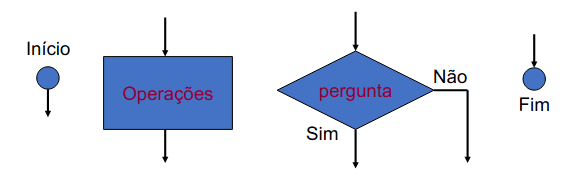
Os fluxogramas são uma notação gráfica usada para especificar o comportamento de uma rotina, tendo como construções fundamentais as seguintes figuras:
Assim, podemos implementar um tratamento de interrupções com o seguinte fluxograma:

E, também podemos obter um para o retorno de interrupções (RFE):
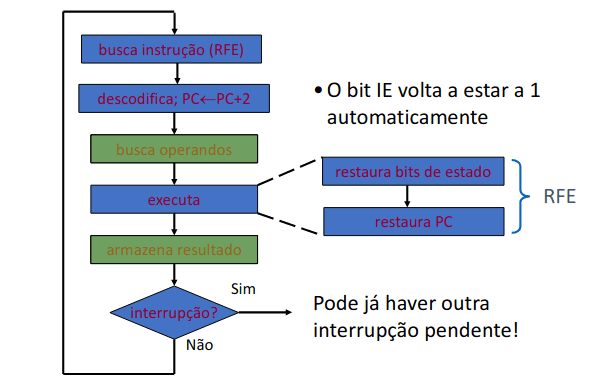
É necessário sublinhar que todas as rotinas de interrupção têm de terminar com RFE.
Programação concorrente
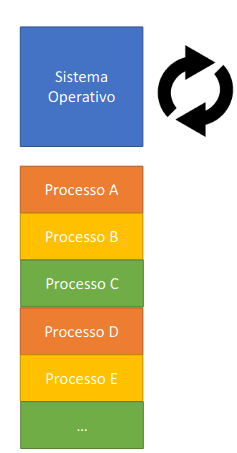
A programação concorrente, tal como o nome nos indica, refere-se a um processador que tenta correr muitos programas diferentes tal como acontece com os computadores modernos. Precisamos de arranjar um forma de programar várias atividades de forma independente. Na prática, um sistema operativo implementa a mudança de processos por meio de interrupção (assíncrona). Contudo, o PEPE é demasiado lento para implementar um sistema operativo, assim, para compensar, o simulador tem suporte para processos.
Espera bloqueante
Um dos principais problemas que temos com a programação concorrente é a espera bloqueante. Um exemplo de uma rotina com espera bloqueante, como pode ser o exemplo em que estamos à espera em que o nosso utilizador carregue numa tecla para iniciar o programa. Ou seja, temos um programa do género:
espera: ; lê a posição de memória ou periférico
CMP valor pretendido ; vê se o valor é o esperado
JNZ espera ; se ainda não é, vai tentar de novo
... ; faz algo caso o valor seja o esperado
RET ; acabou, regressaContudo, o que se deve fazer sem suporte para processos é o seguinte:
espera: ; lê a posição de memória ou periférico
CMP valor pretendido ; vê se o valor é o esperado
JNZ sai ; se ainda não é, há de tentar de novo
... ; faz algo caso o valor seja o esperado
sai: RET ; iteração do ciclo principalOu seja, o nosso programa principal deve ter um ciclo que chama repetidamente as rotinas de todos os processos. A nossa espera à rotina deve ser externa e não interna. Se nenhuma espera tiver ciclos bloqueantes, então todas correm à vez.
Espera não bloqueante
Já que já vimos a espera bloqueante, temos agora que ver exemplos de espera não bloqueante. Começamos por analisar uma rotina com espera bloqueante com suporte para processos cooperativos, neste caso vemos uma mudança é controlada pelo programador:
espera: ; indica ao sistema que aqui pode mudar para outro processo
; lê posição de memória ou periférico
CMP valor pretendido ; vê se valor é o esperado
JNZ espera ; se ainda não é, vai tentar de novo
... ; faz algo caso o valor seja o esperado
RET ; acabou, regressaEmbora a espera seja bloqueante, tem sempre um ponto de fuga, ou seja há uma mudança de processo, caos haja outros processos. Isto permite ao programador programar como se houvesse um sistema operativo que fizesse a mudança automática de processos. Contudo o programador controla o ponto de mudança de processo, se não indicar, fica numa espera bloqueante.
A vantagem é que o ciclo fica interno ao processo, que se programa quase como se não houvesse outros, e não tem de memorizar o estado em que estava entre invocações sucessivas (pelo ciclo do programa principal).
Como concretizar os processos
Existem duas formas de concretizar processos. A primeira opção é concorrência baseada em interrupções. Esta abordagem sem suporte para processos é possível no PEPE, o programador principal tem um ciclo infinito, onde trata, em sequência, as diversas atividades sem temporização de tempo real (CALLs a uma ou mais rotinas). Cada rotina de interrupção implementa cada uma das atividades concorrentes cuja execução deva ocorrer em instantes específicos do tempo, temporização de tempo real.
Vantagens:
- Permite correr múltiplos programas de forma concorrente
Desvantagens:
- Coloca mecanismos de **baixo nível, interrupções, a executar tarefas de alto nível, atividades da aplicação;
- O número de pinos de interrupção limita o número de programas concorrentes;
- Estas rotinas não podem ter ciclos bloqueantes, potencialmente infinitos, pois não permitiriam que as restantes rotinas fossem também executadas;
- Difícil de programar.
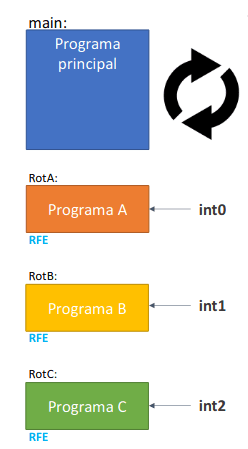
A segunda opção é rotinas cooperativas. Nesta abordagem, cada rotina deve apenas assinalar o que ocorreu, por exemplo, alterando uma variável em memória.
Vantagens:
- Permite correr múltiplos programas de forma concorrente;
- Todo controlo é feito em software, isto é não depende de mecanismos de baixo nível, como as interrupções.
Desvantagens:
- Estas rotinas não podem ter ciclos bloqueantes, potencialmente infinitos, pois não permitiriam que as restantes rotinas fossem também executadas.
- Ainda se deixa muita da responsabilidade da gestão da concorrência nas mãos do programador.
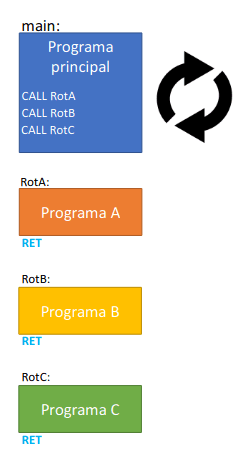
A terceira opção é processos cooperativos. Nesta abordagem o sistema já permite criar processos, que executam de forma autónoma e independente, a tarefa principal é essencialmente criar os processos que depois correm de forma autónoma. Os processos têm de indicar em que ponto dos ciclos potencialmente bloqueantes é que o sistema pode mudar para outro processo, ou seja, os processos controlam onde é que podem largar o processador, por isso são cooperativos.
Vantagens:
- Permite correr múltiplos programas de forma concorrente;
- Todo o controlo é feito em software, isto é, não depende de mecanismos de baixo nível, como as interrupções;
- Já podem ter ciclos bloqueantes, potencialmente infinitos.
Desvantagens:
- Processos têm de ser bem-comportados, mas têm suporte para o fazer;
- Ainda se deixa responsabilidade na gestão dos processos nas mãos do programador.
Por último, a nossa última opção é processos "verdadeiro". Este processo não é possível no PEPE. Um sistema operativo muda automaticamente de processo quando chegar ao fim a sua fita de tempo de execução, o que pode ocorrer em qualquer ponto do conjunto das suas instruções. Um processo não tem indicar nenhum ponto onde a comutação de processo possa ocorrer e pode ser programado assumindo que tem o processador inteiramente para si.
Vantagens:
- Permite correr múltiplos programas de forma concorrente;
- Todo o controlo é feito em software;
- Já podem ter ciclos bloqueantes;
- Processos já não têm de ser bem-comportados;
- Já não se deixa responsabilidade na gestão dos processos nas mãos do programador.
Desvantagens:
- Um sistema operativo é um software complexo que exige um processador com alguma capacidade computacional.
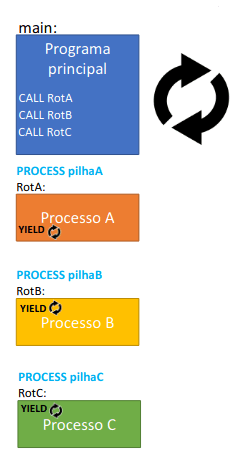
Processos cooperativos no PEPE
No simulador do PEPE, é possível usar-se a diretiva PROCESS antes de uma rotina, indicando o endereço após a pilha, para inicializar o SP.
algures: ... ; instruções algures no programa
CALL rotina ; não invoca a rotina, cria o processo
... ; mais instruções algures no programa
STACK 100H ; declara pilha a usar pelo processo
pilha_rotina: ; endereço inicial para o SP do processo
PROCESS pilha_rotina ; endereço para inicializar o SP
rotina: ... ; instruções do processo (com YIELD, pode ter loops bloqueantes)
RET ; se chegar aqui, termina o processoO CALL à rotina não a invoca, cria o processo, inicializa o seu SP e coloca-o executável. O RET não retorna, termina o processo. Cada processo tem de ter a sua própria pilha, independente das restantes, que deve ser declarada com a diretiva STACK. A diretiva PROCESS deve preceder o label da rotina que implementa o processo. A diretiva PROCESS precisa que se indique qual o valor com que o SP deste processo deve ser inicializado, o que é feito automaticamente. Cada processo fica com uma cópia independente dos registos, a "rotina" do processo não precisa de fazer PUSH nem POP. Dentro da rotina que implementa o processo pode ser colocada a diretiva YIELD, que indica que o simulador pode comutar para outro processo nesse ponto, tipicamente usa-se dentro de ciclos potencialmente bloqueantes.
Contexto dos processos
Para comutar de processo, o simulador guarda internamente todo o estado (contexto) desse processo, todos os registos (PC, RO a R15), de seguida determina qual o próximo processo a executar (dos executáveis). Por último vai buscar o contexto desse processo, carrega-o nos registos e continua a execução, no ponto em que esse processo tinha ficado.
É por causa do contexto que cada processo pode usufruir de uma cópia dos registos só para si, sem ter de os partilhar com outros processos. Os valores dos registos na altura do "CALL" são copiados para o contexto e constituem, na prática, parâmetros para o processo. Fazendo vários "CALL"s à mesma rotina de processo, podem criar-se processos com o mesmo código mas com dados diferentes, número de instância, por exemplo.
Comunicação e sincronização
Os processos só podem comunicar através de variáveis, um pode escrever numa WORD (ou BYTE) e outro ler essa word, isto quer dizer que há uma comunicação, mas não sincronização, pode dar origem a bugs complicados de detetar ou resolver.
A solução é simples: usar variáveis LOCK. São idênticas a WORD, exceto que se um processo ler um LOCK, bloqueia e se um processo escrever num LOCK, desbloqueia todos os processos bloqueados, e a leitura nesses processos devolve o valor escrito. Este mecanismo serve, assim, para sincronização e comunicação.
Exemplo:

Processo vs "device-drivers"
Interfaces com periféricos, por exemplo o teclado, e rotinas de interrupção são mecanismos de baixo nível (“device-drivers”), que devem ser independentes das aplicações de alto nível (processos) que os usam. Por isso, não devem ter conhecimento das aplicações e devem-se limitar a interfaces com periféricos, ler ou escrever valores de e para os periféricos sem saber qual o seu significado e a rotinas de interrupções, assinalarem que a interrupção ocorreu.
Devem ser os processos, alto nível, a ter semântica da aplicação. Para um processo esperar por uma dada informação "de baixo nível", por exemplo uma tecla carregada ou uma temporização; estas podem estar sempre a testar algo, o que é má ideia, ou bloqueiam-se num LOCK o que é melhor ideia.
Otimização de polling
Mesmo assim, o processo teclado está continuamente a varrer o teclado (polling), mesmo que ninguém esteja a carregar numa tecla. Os sistemas operativos têm mecanismos para evitar isto e funcionar por eventos (ocorrências). O simulador tem algo correspondente, embora muito mais simples: a diretiva WAIT.
É semelhante ao YIELD, a diferença é que faz o processador adormecer se não houver mais processos executáveis, e acorda com algum evento no sistema. Assim, o processador só corre quando há eventos e no resto do tempo fica em WAITING.