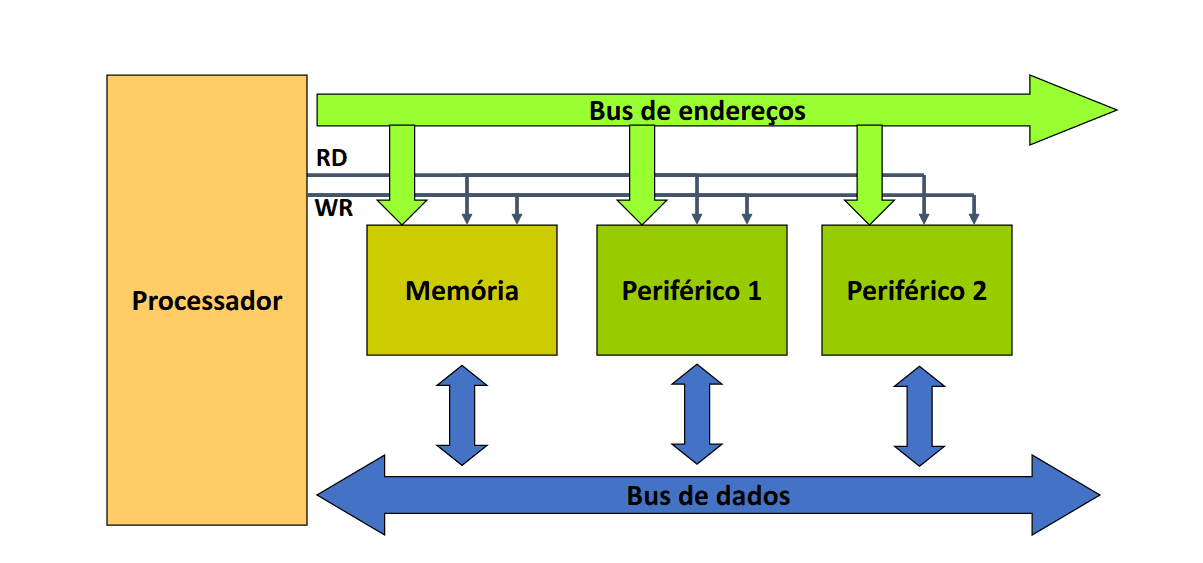
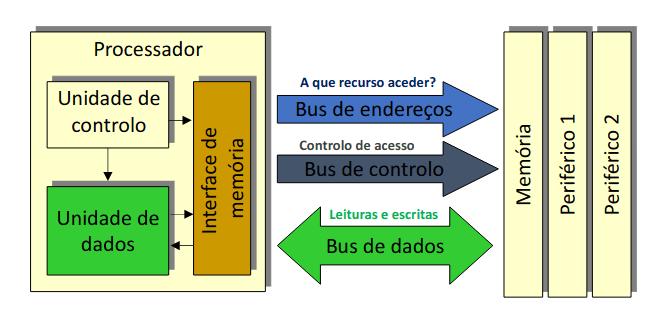
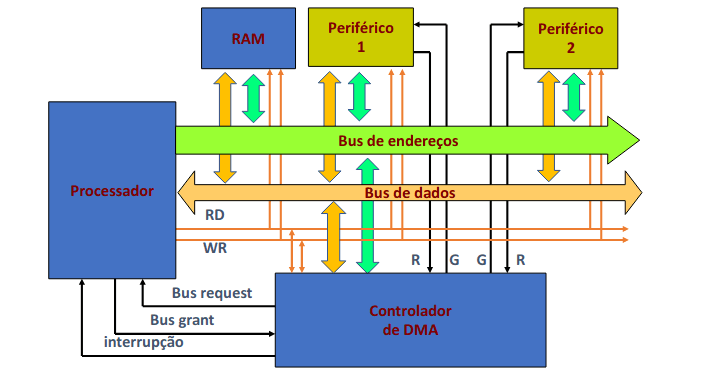
Como podemos ver na imagem acima, temos um barramento (bus) de dados e de endereços que estão conectados com o processador. Este barramento representa um meio físico de interligação dos vários dispositivos.
A questão que se coloca é que correspondência é que faa, ou seja, liga o os processadores ao quê? Os barramentos estabelecem um acesso ao exterior do processador, isto visto que o processador especifica um endereço mas não sabe se é memória ou periférico.
Descodificação de endereços
Visto que as memórias e os periféricos coexistem no mesmo espaço de endereços, como é que é possível distingui-los? Cada dispositivo liga os bits de menor peso do bus de endereços, assim o descodificador de endereços liga os bits de maior peso do bus de endereços e gera os chip select (CS) e, quando está ativo, significa que o dispositivo está a ser acedido.
Exercício
Supondo que temos um processador de 8 bits como o mapa de endereços abaixo, responda às seguintes questões:
Quantos bits deve ter no mínimo o bus de endereços?
No mínimo deve ter 24 bits.
Qual o espaço de endereçamento deste mapa de endereços?
Tem 16 MiB de espaço.
Qual a capacidade da RAM?
Tem 2 MiB de capacidade.
Qual a capacidade da ROM?
Tem 8 MiB de capacidade.
Qual o espaço reservado para periféricos?
Tem 4 KiB de espaço reservado.
Qual o espaço livre?
Tem entre 6 MiB a 4 KiB de espaço livre.
Quantos bits de endereçamento devem ligar a cada módulo de RAM?
Devem ligar 20 bits.
E à ROM?
Devem ligar 23 bits.
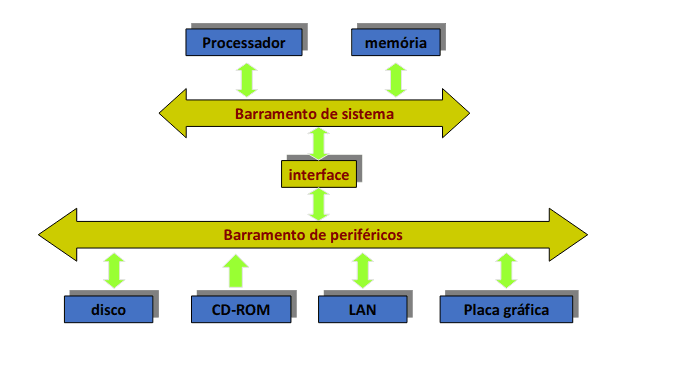
Arquitetura do sistema de periféricos
Temos, contudo, um problema: como o desempenho dos processadores, ou seja a frequência do seu relógio, aumentou muito rapidamente, tornou-se impraticável a ligação direta a todos os periféricos, que são, em regra geral, muito mais lentos. Como podemos resolver a situação? Com barramentos hierárquicos.
Modos de transferência de dados
Temos vários modos de transferência de informação entre o processador/memória e os periféricos diferentes, nomeadamente sob controlo do programa, ou seja o polling, por interrupção, por acesso direto à memória (DMA- Direct Memory Access ou até mesmo com um co-processador de entradas/saídas.
Num extremo, no polling, o processador trata de tudo, no outro, o processador limita-se a programar o co-processador. Dado que as entradas/saídas são lentas, a ideia é reduzir o tempo que o processador gasta à espera dos periféricos (libertando-o para outras tarefas).
Polling
Neste modo de transferência de dados, o programa controla tudo; faz espera ativa contínua, senão pode perder dados, sobre periféricos lentos. A transferência é feita por software. O único problema é ser muito ineficiente: o processador poderia estar a executar outras tarefas em vez de estar à espera de dispositivos lentos.
Transferência por interrupção
Em transferência por interrupção temos uma espera não ativa: o processador só é "incomodado" quando há coisas para fazer. A vantagem é ser mais eficiente, contudo, tem como desvantagem que a transferência de dados, por software, pode ser lenta.
DMA (Direct Memory Access)
A transferência de informação entre o processador/memória e os periféricos é feita em hardware por um controlador especializado. O processador só tem de programar o controlador de DMA, escrevendo em portos próprios do controlador, que em si também é um periférico, o endereço de origem, o endereço de destino, o número de palavras a transferir e qual o modo de DMA.
Durante a transferência, os endereços de origem e destino são incrementados automaticamente. Assim, ficamos com um controlador de DMA:
Lidar com vários periféricos
Um computador tem normalmente vários periféricos e pode misturar os vários modos de transferência de dados. Deve-se ter atenção qie a transferência sob controlo do programa, o polling, deve ser reservada para periféricos lentos, sem temporizações críticas e com protocolos que possam ser interrompidos, a transferência por interrupções é mais eficiente, mas mais pesada para transferência de grandes quantidades de informação (a transferência em si é feita por software) e a transferência por DMA (ou com co-processador) é a mais eficiente, mas o processador pode não conseguir atender interrupções durante uma transferência.
Periféricos de comunicação: barramentos
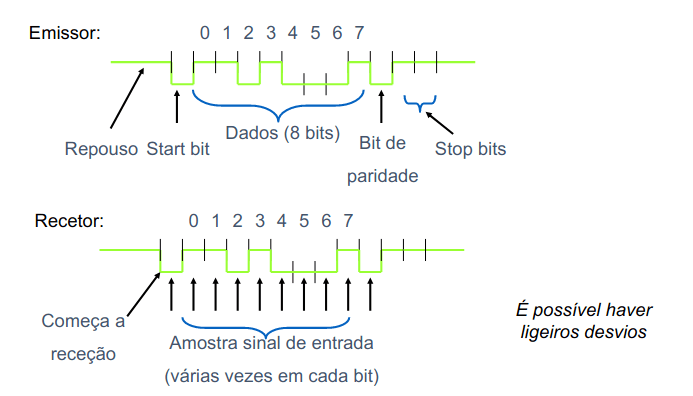
Começamos com um exemplo: barramentos série assíncrono. A comunicação é orientada ao byte, que é serializado. O barramento está normalmente em repouso (1), quando o emissor decide transmitir coloca a linha a 0 durante um bit (start bit), envia os 8 bits do byte em sequência, envia um bit de paridade (para deteção de erros), envia de 1 a 2 stop bits a 1 (para sincronização). A cadência de transmissão dos bits (baud-rate) tem de ser aproximadamente a mesma em todos os dispositivos no barramento (não tem de ser exatamente igual).
Assim, o assincronismo deriva do tempo arbitrário entre bytes. Usa-se em aplicações de baixo ritmo de transmissão (sistema de controlo, por exemplo).
Comunicação série assíncrona
Há diversas baud-ratesnormalizadas:
110 bit/s;
75 bit/s e seus múltiplos 150, 300, 600, 1200, 2400, 4800, 9600, 19200,
38400;
14400 bit/s e seus múltiplos: 28800, 43200, 57600
Também teremos outros parâmetros, ou seja, a paridade (ser par, ímpar ou nenhuma) e os stop bits (1, 1.5 ou 2). Também é importante referir que já existem chips que implementam este protocolo, nomeadamente UART (Universal Asynchronous Receiver and Transmitter) e USART (suporta também o protocolo síncrono).
Desempenho
A melhor forma de medir o desempenho de um processador (relativamente a outros) é a medir o tempo de execução de um programa. Ficamos com uma equação básica:
T=FN×D
Seja o T o tempo de duração do programa, o N o número de instruções no programa, o D a duração média (em ciclos de relógio) de casa instrução (CPI, Clock Cycles per Instruction) e o F é a frequência do relógio (ciclos/segundo).
Os limites do desempenho
N, F e D, não são independentes:
Para reduzir N, cada instrução tem de fazer mais, o que pode aumentar D e/ou reduzir F;
Para reduzir D, as instruções têm de ser mais simples, o que obriga a ter mais instruções para fazer o mesmo;
Para aumentar F (sem melhorar a tecnologia), só com uma arquitetura mais simples, o que obriga a aumentar N.
Um processador de F = 2 GHz pode ser mais rápido do que outro de F = 2.5 GHz, se tiver um menor valor de D ou de N.
Os processadores têm evoluído por:
melhor tecnologia (F mais elevado);
melhor arquitetura (menor valor de D);
melhores compiladores (menor valor de N).
Avaliação do desempenho
Temos um problema típico: comparar o desempenho de dois ou mais computadores. Para comparar os fatores individuais não faz sentido, porque são dependentes uns dos outros. Temos que usar uma métrica simples: MIPS (Mega Instructions Per Second), ou seja o fator F/D não chega, o valor de N pode ser diferente.
Os fabricantes divulgam normalmente o valor máximo do MIPS e não médio, porque depende do peso relativo da ocorrência das várias instruções. Mas, um computador não é apenas o processador.
Quando estamos a comparar dois carros, não interessa apenas medir a rotação máxima ou a potência do motor, temos que analisar o resultado global da sua utilização. Da mesma forma, em computadores, em vez de MIPS usam-se benchmarks, que são programas que exercitam os vários aspetos de um computador (processador, memória e periféricos). O valor do benchmark indica o número de vezes/segundo que o benchmark executa.
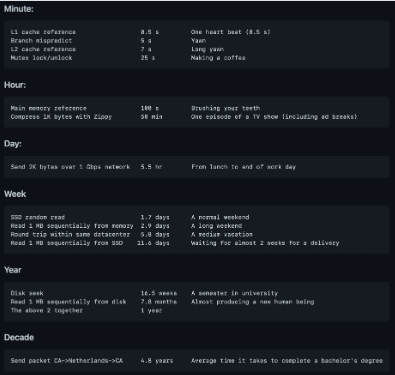
A limitação dos periféricos
Contudo, os periféricos têm algumas limitações. Começamos por referir as taxas de transferências típicas:
Teclado (depende de quem está a teclar) – 10 bytes/seg;
LAN, 100 Mbits/seg – 12.5 Mbytes/seg;
LAN, 100 Gbits/seg – 12.5 Gbytes/seg;
Disco – 100 Mbytes/seg a 300 Mbytes/seg;
Bus de dados a 200 MHz (64 bits) – 1,6 Gbytes/seg;
Registos internos a 2 GHz (64 bits) – 16 Gbytes/seg
De seguida, um processador com o dobro do relógio não corre necessariamente programas com metade do tempo. Isto porque o tempo total é igual ao tempo de execução em memória mais o tempo periférico.
Por último, se o tempo gasto à espera dos periféricos for de 50%, duplicar a velocidade do processador apenas reduz o tempo total em 25%.
A lei de Amdahl
Assumindo que se melhora um fator que afeta apenas oarte do tempo de execução, ficamos com a fórmula:
Tempo melhorado=Nº de vezes mais raˊpidoTempo parte afetada+Tempo parte na˜o afetada
Mesmo que se melhore um dos fatores, por exemplo a velocidade do processador, os restantes podem limitar severamente a melhoria global. Assim, deve-se procurar otimizar os fatores usados mais frequentemente, isto é, com mais peso no programa.
Medidas de desempenho do I/O
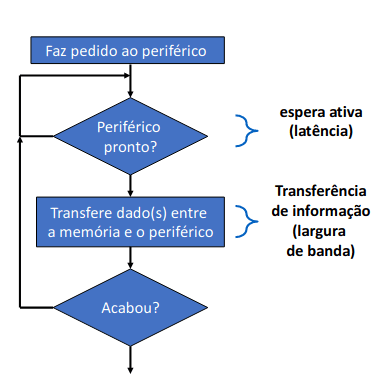
Temos que ter em consideração que existem duas grandezas fundamentais:
Latência: o tempo até se iniciar a transferência (relacionado com o tempo de procura de informação, tempo de inicialização do canal de transferência, etc)
Largura de banda: máxima quantidade de informação transferida por unidade de tempo.
Cada acesso a um periférico inclui um período de latência e outro de transferência. A velocidade de transferência efetiva (média) depende do peso relativo da latência.
Comunicação via rede
Existem diversos fatores fundamentais na comunicação, nomeadamente tempo de acesso à informação (disco, por exemplo), tempo de processamento local (normalmente desprezável, mas pode ser importante se os dados tiverem muito processamento, como a compressão, por exemplo) e o tempo de comunicação (tal como o acesso aos discos, inclui latência e tempo de transmissão). O tempo total de comunicação é o somatório destes tempos parciais e, normalmente, o fator limitativo é o disco, mas uma rede lenta pode estrangular a comunicação.