Instruções: Linguagem de um Computador
ISA: Instruction Set Architecture
Como já tínhamos visto anteriormente, os computadores funcionam através de sets de instruções e diferentes computadores têm diferentes conjuntos de instruções. Contudo, estes conjuntos têm muitos aspetos em comum. Assim, temos que introduzir o conceito de ISA (Instruction Set Architecture), que se refere à interface abstrata entre o hardware e o software de nível mais baixo, e que engloba toda a informação necessária para escrever um programa em linguagem máquina.
CISC vs RISC
Como é que podemos distinguir as diferentes arquiteturas de instruções que um computador pode ter e qual delas é a mais favorável ao nosso objetivo final? Existem duas arquiteturas nas quais nos vamos focar nesta cadeira: CISC (Complex Instruction-Set Computer) e RISC (Reduced Instruction-Set Computer). Nas arquiteturas mais recentes, o ISA é uma mistura das duas, que são regularizadas através de uma pipeline.
Mas o que diferencia estas duas arquiteturas?
- Número de instruções;
- Complexidade das operações que são implementadas por uma única instrução;
- Número de operandos;
- Modos de endereçamento;
- Acesso à memória.
MIPS-32 ISA
Nesta cadeira, vamos usar o processador MIPS como principal exemplo de um processador. Este processador foi desenvolvido por parte do programa de investigação VLSI na Stanford University no início da década de 80. O objetivo do MIPS era ter um processador cuja arquitetura pudesse representar como se baixava o compilador para o nível do hardware em vez de se elevar o hardware ao nível do software. Assim, este processador implementa um set de instruções mais pequeno e mais simples que, através de pipelining, produzem um processo mais eficiente de instruções.
Assim, conseguimos obter um processador que:
-
Favorece a simplicidade através de um tamanho pré-definido para as instruções, um número pequeno de formato de instruções e um opcode sempre definido nos primeiros 6 bits;
-
Acredita que mais pequeno é mais rápido através de um set limitado de instruções, um número limitado de registos no ficheiro de registos e um número limitado de modos de endereçamento;
-
Apresenta um bom design com bons compromissos, visto que temos três formatos de instruções (instruções , , );
-
Torna o caso comum mais rápido, já que as nossas operações aritméticas estão no ficheiro de registos (load-store machine) e as instruções contêm um operando imediato;
Este último já tinha sido referido ao ser dada a Lei de Amdahl e um bom exemplo de termos este princípio em mente é se, por exemplo, num programa, fizermos mais somas que qualquer outra operação. Como grande parte da execução do programa é passada a somar valores, devemos otimizar estas operações. Se para além das somas tivéssemos apenas uma multiplicação que corresse num tempo muito maior em comparação com as somas, poderíamos pensar que vale a pena otimizarmos esta operação em vez da nossa soma, mas estaríamos errados. Isto porque se fazemos mais somas que multiplicações, por exemplo em comparação com respetivamente, não vale a pena estarmos a otimizar a multiplicação, sabendo que otimizar a operação de soma seria muito mais vantajoso.
Categorias de Instruções
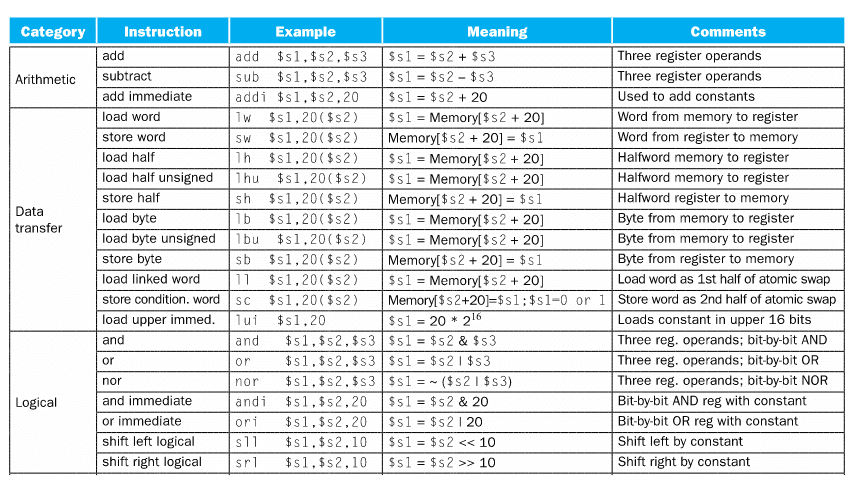
Tal como já tinha sido visto em IAC, quando falamos sobre Assembly, temos diferentes categorias de instruções para conseguirmos escrever código:
- Computacional;
- Load/Store;
- Jump e Branch;
- Floating Point;
- Memory Management;
- Especial.

Como podemos ver acima, existem três tipos de instruções, cada uma com um formato diferente. Alguns dos conceitos que se devem saber são:
- op: operação que estamos a realizar;
- rs, rt e rd: registos com valores que vamos usar, sendo que os dois primeiros são de origem (source, t (letra seguinte a s)) e o último de destino (destination);
- funct: função auxiliar a alguns opcodes;
- immediate: uma constante;
- jump target: endereço para o qual queremos saltar.
O PC refere-se a Program Counter, que indica o endereço de memória no qual o processador está a ler a instrução atual. Este é incrementado sempre de em bytes (porque uma instrução ocupa bits e byte bits).
Operações Aritméticas em Assembly
Tal como já tínhamos visto em IAC, há várias operações que podemos fazer no nosso programa.
Adição e Subtração
Para fazermos estas duas operações aritméticas, temos que usar três operandos, dois que nos indicam os valores a adicionar/subtrair e um onde vamos guardar o valor final. Todas as operações aritméticas têm esta forma:
a = b + c; → add a, b, c → a recebe b + c
d = a - e; → sub d, a, e → d recebe a - e
Tarefa complexa em C
# C code
f = (g + h) - (i + j);# Assembly code
add $t0, $s0, $s1 # variável temporária t0 contém g + h
add $t1, $s2, $s3 # variável temporária t1 contém i + j
sub $t2, $t0, $t1 # t2 recebe t0 - t1MIPS - Registos
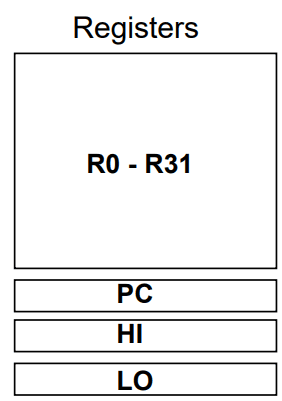
O MIPS tem registos. O banco de registos tem portas de leitura e porta de escrita, o que nos permite ler valores de dois registos e, simultaneamente, escrever um valor num registo. Cada registo armazena uma palavra de bits, isto é, bytes.
Uma grande vantagem dos registos é a sua velocidade de acesso, que é muito superior à da memória principal, ou mesmo à das caches (como veremos mais à frente). No entanto, é preciso efetuar trade-offs quanto ao número de registos, pois o tempo de acesso aumenta com o aumento do número de registos. Por exemplo, um banco de registos que guarda registos pode ser até mais lento do que um que guarde apenas . O mesmo se aplica à quantidade de portas de leitura e escrita, dado que adicionar mais portas aumentaria o tempo de acesso de forma quadrática.
Outra vantagem dos registos é o seu pequeno endereço.
Como existe um número muito reduzido de registos, são necessários poucos
bits para os endereçar (num banco de registos, são necessários bits).
Isto reduz o tamanho das instruções e aumenta a densidade do código, dado que
também não é necessário efetuar LOAD e STORE como na memória.
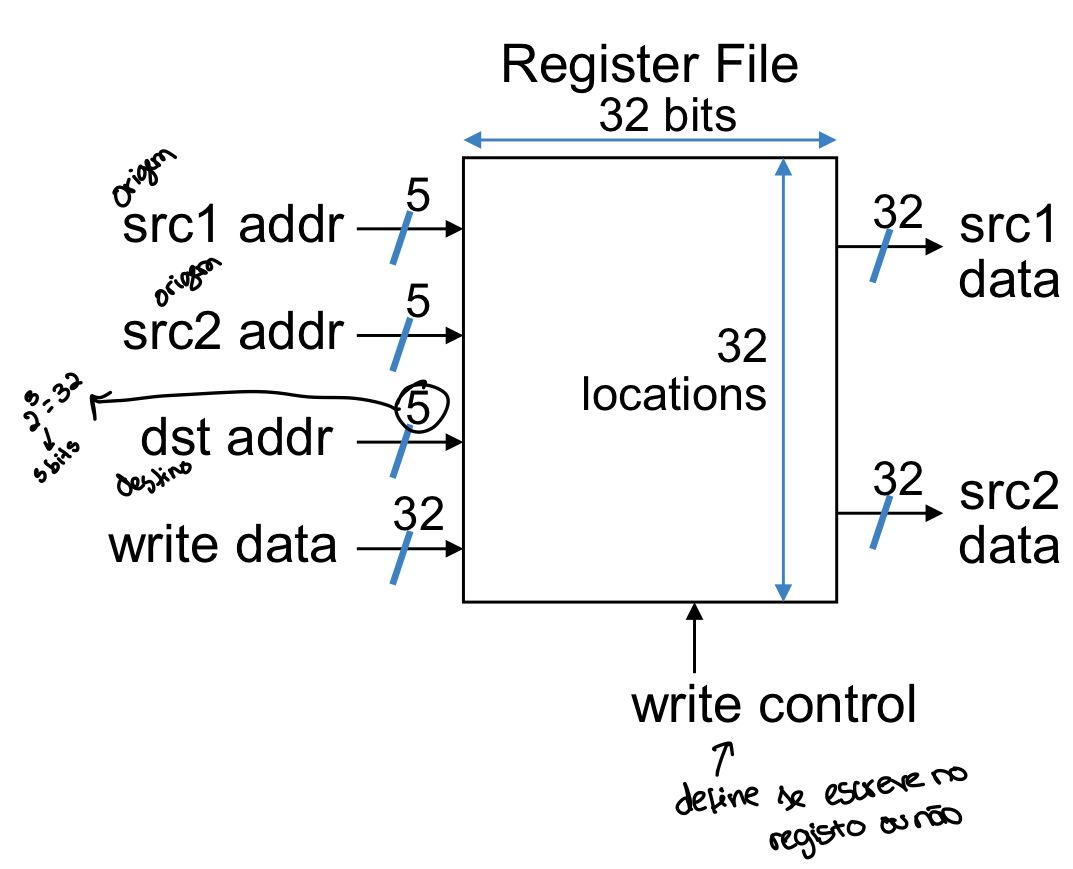
No MIPS, existe a seguinte convenção de registos:
| Nome | Número do Registo | Descrição | Preservado num JAL/interrupção? |
|---|---|---|---|
$zero |
0 | é uma constante, vale sempre zero | n.a. |
$at |
1 | reservado para o assembler | n.a. |
$v0 a $v1 |
2 e 3 | valores de retorno | não |
$a0 a $a3 |
4 a 7 | argumentos de funções | sim |
$t0 a $t7 |
8 a 15 | valores temporários | não |
$s0 a $s7 |
16 a 23 | valores a guardar | sim |
$t8 a $t9 |
24 e 25 | (mais) valores temporários | não |
$k0 a $k1 |
26 e 27 | reservados para tratamento de exceções | não |
$gp |
28 | ponteiro global (global pointer) | sim |
$sp |
29 | ponteiro da pilha (stack pointer) | sim |
$fp |
30 | frame pointer | sim |
$ra |
31 | endereço de retorno | sim |
Instruções com Formato

op: código de operação - opcoders: número do primeiro registort: número do segundo registord: número do registo de destinoshamt: quantidade de shift ("00000", por agora)funct: código de função - extensão do opcode
Exemplo

Olhando para a imagem acima, podemos fazer a soma dos valores dos dois registos, guardando o valor em , através do comando:
add $t0, $s1, $s2Assim, obtemos a nossa instrução em código máquina, em base hexadecimal.
Operandos Imediatos

Sempre que temos uma constante, estamos perante um operando (imediato). Como indica o formato da instrução, a constante é guardada mesmo na instrução. Isto resulta num tamanho máximo de bits, ou seja, de até (quando a constante é signed).
op: código de operação - opcoders: número do registo de origemrt: número do registo de destinoimmediate: constante guardada
Exemplo
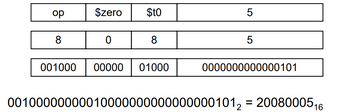
Olhando para a imagem acima, podemos fazer a soma do valor no registo , que é sempre , com a constante, guardando o valor em , através do comando:
addi $t0, $zero, 5Subtração Imediata
Não existe subtração imediata, pelo que temos que usar uma adição imediata com uma constante negativa.
addi $s2, $s1, -1 # guarda em $s2 o valor de $s1 - 1Load de Constantes de 32 bits
Como as instruções de tipo (immediate) apenas suportam constantes de bits, necessitamos de duas instruções para carregar valores de bits.
-
Carregamos os bits de ordem superior ( a ) primeiro, com a instrução load upper immediate.
lui $t0, 0b1010101010101010Neste momento, temos
$t0 = 1010 1010 1010 1010 0000 0000 0000 0000. -
Carregamos os bits de ordem inferior ( a ) em segundo lugar, com a instrução or immediate.
ori $t0, $t0, 0b0101010101010101Ficamos assim com
$t0 = 1010 1010 1010 1010 0101 0101 0101 0101.
Números binários
Nesta cadeira, tal como em IAC, vamos ver números binários. Para tal, é recomendado rever essa matéria na tab dos resumos de Introdução à Arquitetura de Computadores.
Para realizarmos uma operação sem complemento para 2,
temos que adicionar um u (unsigned) ao nome da operação.
São exemplos disto addu, addiu, subu, etc...
Operações Lógicas
| Operação | C | Java | MIPS |
|---|---|---|---|
| Shift left | << |
<< |
sll |
| Shift right | >> |
>>> |
srl |
| Bitwise AND | & |
& |
and,andi |
| Bitwise OR | | |
| |
or, ori |
| Bitwise NOR | ~(|) |
~(|) |
nor |
Estas operações são usadas na manipulação de bits e são úteis para extrair ou inserir grupos de bits numa palavra.
Operações de Deslocamento

É importante referir que o shamt corresponde ao número de posições que pretendemos avançar ou recuar.
O shift left ajuda-nos a fazer multiplicações de pois avança casas para a esquerda e adiciona os zeros que faltam. O shift right ajuda-nos a fazer divisões de pois avança casas para a direita e adiciona os zeros que faltam.
Exemplo
Imaginemos que queremos multiplicar um valor por ().
Então, podemos fazer o seguinte shift:
sll $t0, $t0, 3Instruções de Acesso a Memória
A memória principal é usada para guardar tanto dados simples (e.g. inteiros, bytes, etc) como dados compostos, tais como arrays, estruturas e dados dinâmicos.
A memória do MIPS é endereçada em bytes, ou seja, cada endereço identifica 8 bits. É muito importante que as palavras estejam alinhadas em memória com um endereço que seja um múltiplo de quatro, de forma a preservar a eficiência do processador e evitar bugs. Usualmente, o compilador trata disto por nós.

O MIPS é uma arquitetura Big Endian,
isto é, em memória e registos, o byte mais significativo está no primeiro endereço de uma palavra.
Pelo contrário, uma arquitetura Little Endian teria, em memória e registos,
o byte mais significativo no último endereço da palavra.
Para efetuar operações aritméticas, precisamos de colocar valores em registos, visto que não é possível efetuar operações sobre valores em memória. Existem instruções tanto para carregar (load) os valores da memória para registos como para guardar (store) os valores de registos em memória.
O MIPS tem duas instruções básicas de transferência de dados para aceder a memória:
lw $t0, 4($s3) # load word from memory
sw $t0, 8($s3) # store word to memoryO número junto ao segundo registo corresponde ao offset. É particularmente útil quando queremos aceder a posições consecutivas de memória, pois evitamos ter de incrementar/decrementar o valor do registo que aponta para o endereço na memória. Devido ao tipo de instrução (I, immediate), o valor do offset é um inteiro signed de bits.
Exemplo
Imaginemos que queremos carregar três palavras da memória que estão em endereços
consecutivos. Sabemos que a palavra do meio tem o endereço 0x4f.
Como cada palavra tem bytes, vamos ter o seguinte código.
ori $t0, $zero, 0x4f # carregar o valor 0x4f para $t0
lw $s0, -4($t0) # endereço 0x4b
lw $s1, 0($t0) # endereço 0x4f
lw $s2, 4($t0) # endereço 0x53Além disso, existem várias variações destas instruções, que nos permitem carregar/guardar half-words e bytes, tais como load byte, load byte unsigned, load half-word, load half-word unsigned, store byte e store half-word.
lb rt, offset(rs)elh rt, offset(rs), em que o sinal é estendido para bits emrtlbu rt, offset(rs)elhu rt, offset(rs), em que o zero é estendido para bits emrtsb rt, offset(rs)esh rt, offset(rs), que guardam os e , respetivamente, bytes menos significativos do registo
Instruções de Controlo
Como já vimos acima com as operações lógicas e aritméticas, também temos que ver as instruções de controlo.
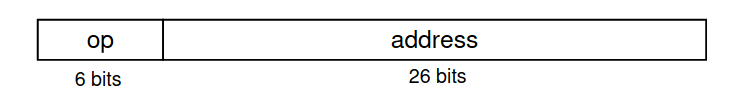
Exemplos deste tipo de intruções são:
- Jump (
j): salta para um endereço em qualquer* parte do programa; - Jump Register (
jr): salta para o endereço que está no valor de um registo; - Jump and Link (
jal): é igual ao Jump, mas guarda no registo$rao valor dePC + 4e é normalmente usado para chamadas a funções.
*: dado que a instrução só suporta um endereço de bits, só conseguimos saltar na mesma "secção" do programa. Conseguimos recuperar bits, dado que cada instrução tem bytes, pelo que os bits menos significativos são sempre zero. No entanto, ficamos com bits (os mais significativos) que não conseguimos controlar, pelo que estes são derivados do PC atual. Daí, só conseguimos saltar dentro de uma certa região do programa (embora esta seja muito grande).
Exemplo
Imaginando que estamos no .
Se efetuarmos um Jump para a instrução , vamos acabar no endereço .
Operações Condicionais
Ao contrário das instruções de Jump, as instruções de Branch são saltos relativos. São instruções de tipo (immediate), pelo que têm um offset de bits.
As operações condicionais não têm state flags, pelo que todos os valores têm de ser guardados em registos próprios.
Um branch salta para uma instrução se a condição for verdadeira, caso contrário continua sequencialmente.
Existem apenas duas instruções de branch, uma para igualdade e outra para desigualdade:
- branch if equal:
beq rs, rt, L1Funciona comoif (rs == rt) branch to L1 - branch if not equal:
bne rs, rt, L1Funciona comoif (rs != rt) branch to L1
Se quisermos efetuar outro tipo de condições, como maior e menor, temos de usar
as instruções set if less than ou set if less than immediate.
É de realçar que não existem instruções no hardware para efetuar
saltos com comparações >, <, >=, <=, etc.
- set if less than:
slt rd, rs, rt
Funciona comoif (rs < rt) rd = 1; else rd = 0 - set if less than immediate:
slti rd, rs, constant
Funciona comoif (rs < constant) rd = 1; else rd = 0
Existem, no entanto, pseudo-instruções, que o assembler desdobra
em duas, um set if less than (immediate) e um branch if (not) equal.
É para isto que serve o registo reservado $at.
- less than:
blt $s1, $s2, Label - less than or equal to:
ble $s1, $s2, Label - greater than:
bgt $s1, $s2, Label - great than or equal to:
bge $s1, $s2, Label
As instruções de Branch são do tipo (immediate).

Ao fazermos um branch, o endereço de destino é dado por , visto que o PC é sempre incrementado em múltiplos de .
Jump e Branch
Apesar de um Branch e um Jump fazerem sensivelmente a mesma coisa, um Jump refere-se a um salto absoluto e incondicional, enquanto que um Branch é um salto relativo e condicional. Para além disso, podemos não conseguir fazer saltos muito longos: num jump, temos bits, enquanto que num branch temos bits, ambos inferiores aos bits necessários para endereçar todas as instruções possíveis.
Caso tentemos fazer um branch para uma instrução que está demasiado longe, o assembler vai reescrever o nosso código com um jump:
beq $s0, $s0, L1 # L1 está muito longe!O assembler vai inverter a condição e inserir um jump:
bne $s0, $s1, L2 # A condição é invertida para que
j L1 # a instrução seguinte seja o salto.
L2: ... # L2 aponta para as instruções
# que se seguiam ao beq.Compilar em Assembly
Tal como vimos nas outras linguagens de programação, existem várias operações simples que conseguimos recriar em Assembly mesmo sem as instruções específicas, através da composição de instruções.
If statements
Considere-se o seguinte código em C.
if (i == j) {
f = g + h;
} else {
f = g - h;
}Em Assembly, teríamos de considerar a seguinte lógica.

Invertemos a condição para saltar diretamente para o else caso a condição falhe.
Caso contrário continuamos a execução, que corresponderia ao corpo do if.
bne $s3, $s4, Else
add $s0, $s1, $s2
j Exit
Else: sub $s0, $s1, $s2
Exit: ...
Loop statements
Considere-se o seguinte código em C.
while (save[i] == k) {
i += 1;
}Sabe-se que:
iestá guardado em$s3- endereço de
saveestá guardado em$s6 kestá guardado em$s5
Como não existe while em Assembly, temos que fazer:
Loop: sll $t1, $s3, 2 # cada elemento da array são 4 bytes
add $t1, $t1, $s6 # somar offset ao endereço de "save"
lw $t0, 0($t1) # ler da memória
bne $t0, $s5, Exit # verificar condição de loop (invertida)
addi $s3, $s3, 1 # efetuar corpo do loop
j Loop # voltar ao início do loop
Exit: ...
Blocos básicos
Um bloco básico é uma sequência de instruções que não têm branches, exceto no final, nem são um destino de branches, exceto no início. Por outras palavras, é um bloco de código que é executado sempre sequencialmente.
O compilador identifica blocos básicos para otimização e um processador avançado consegue acelerar a sua execução.
Resumo Instruções MIPS