Comunicação entre Processos
Quando estamos a programar concorrentemente, podemos fazê-lo segundo dois paradigmas:
- Por Memória Partilhada
- Tarefas partilham dados (no heap/amontoado)
- Troca de dados é feita escrevendo e lendo da memória partilhada
- Sincronização recorre a mecanismos adicionais (e.g., trincos, semáforos, ...).
- Por Troca de Mensagens
- Cada tarefa trabalha exclusivamente sobre dados privados
- Tarefas transmitem dados trocando mensagens
- Mensagens também servem para sincronizar tarefas
Analogia
Edição concorrente de um documento:
Memória partilhada (como Google Docs):
- Única cópia online do documento: dados partilhados;
- As alterações de um editor são imediatamente aplicadas ao documento partilhado e visíveis logo aos outros editores.
Troca de Mensagens
- Cada editor mantém uma cópia privada do documento no seu computador;
- Alterações enviadas por email e aplicadas independentemente.
Porquê Diferentes Paradigmas?
-
Historicamente algumas arquiteturas só permitiam que programas a correr em CPUs distintos trocassem mensagens (cada CPU tinha a sua memória privada, estando os vários CPU interligados por uma rede), enquanto que outras suportavam memória partilhada (e.g. CPUs podiam aceder à mesma memória RAM através de protocolo de coerência de cache).
-
A existência dos diferentes paradigmas permite estilos diferentes de programação, com virtudes e defeitos:
- Existência de diferentes ambientes de programação mais apropriados para cada paradigma;
- Maior ajuste às preferências de cada programador;
- Alguns problemas mais fáceis de resolver eficientemente num paradigma que noutro.
Combinações de Modelos de Paralelismo e Coordenação
Até agora foram estudados:
-
Dois modelos de paralelismo:
- por tarefa
- por processo
-
Dois modelos de concorrência:
- por troca de mensagens
- por memória partilhada
Os modelos de paralelismo e concorrência podem ser combinados!
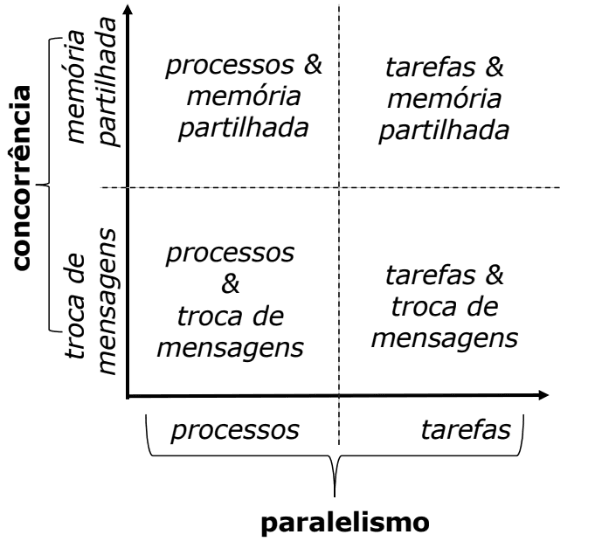
Anteriormente vimos como comunicar entre Tarefas através de Memória Partilhada e Tarefas. Agora iremos ver como comunicar entre Processos através Troca de Mensagens.
Comunicação por Troca de Mensagem
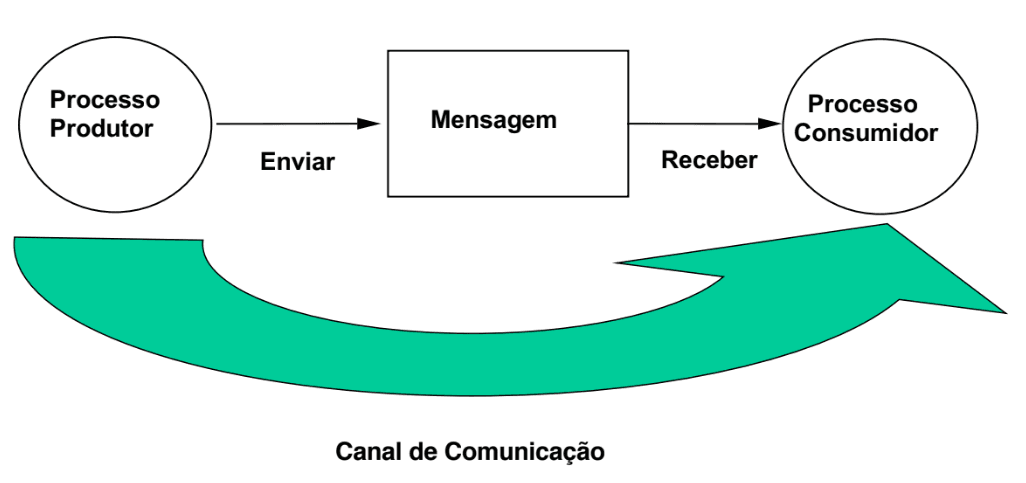
A comunicação entre processos pode realizar-se no âmbito:
- de uma única aplicação;
- entre aplicações numa mesma máquina;
- entre máquinas interligadas por uma redes de dados.
Exemplos
- servidores de base de dados;
- browser e servidor WWW;
- cliente e servidor SSH;
- cliente e servidor de e-mail;
- nós BitTorrent.
Implementação de um Canal de Comunicação
Um canal de comunicação pode ser implementado a dois níveis:
- No núcleo do sistema operativo: os dados são enviados/recebidos por chamadas sistema
- No user level: os processos acedem a uma zona de memória partilhada entre ambos os processos comunicantes
Por Memória Partilhada
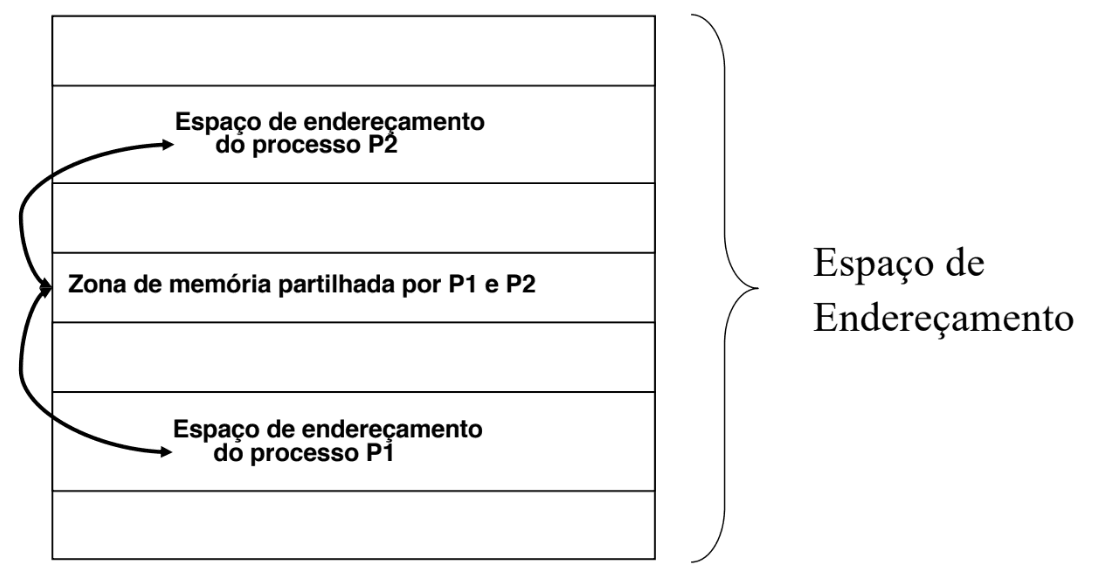
Cópia Através do Núcleo

Iremos começar por falar neste última forma de implementação
Unix - Modelo Computacional - IPC
Pipes
Os pipes são o mecanismo original do Unix para comunicação entre processos.
Correspondem a um canal anónimo unidirecional (byte stream) ligando dois processos.
Os pipes podem ser referenciados por um processo através dos seus descritores, que são internos ao processo, podendo ser transmitidos para os processos filhos através do mecanismo de herança.
Os descritores de um pipe são análogos ao dos ficheiros:
- As operações de read e write sobre ficheiros são válidas para os pipes;
- O processo fica bloqueado quando escreve num pipe cheio;
- O processo fica bloqueado quando lê de um pipe vazio.
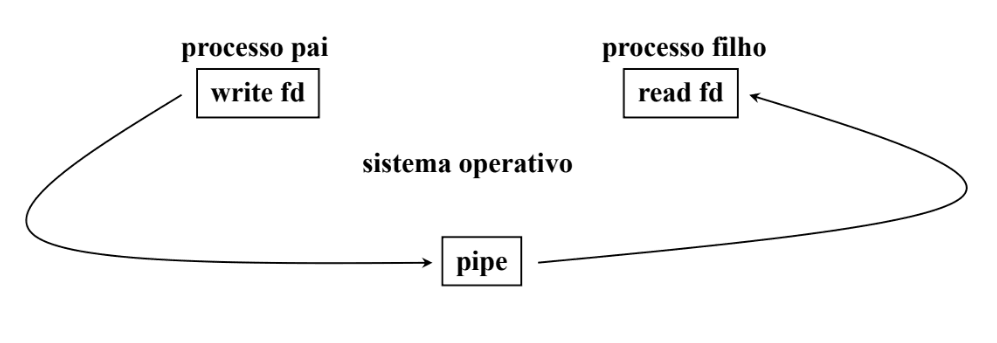
Exemplo: Comunicação Pai-Filho
#include <stdio.h>
#include <fnctl.h>
#define TAMSG 100
char msg[] = "mensagem de teste";
char tmp[TAMSG];
main() {
int fds[2], pid_filho;
// fds[0] - descritor aberto para leitura
// fds[1] - descritor aberto para escrita
if (pipe(fds) < 0) exit(-1); // Criação de um pipe
if (fork() == 0) {
/* processo filho*/
close(fds[1]);
/* lê do pipe */
read(fds[0], tmp, sizeof (msg));
printf("%s\n", tmp);
exit(0);
} else {
/* processo pai */
close(fds[0]);
/* escreve no pipe */
write(fds[1], msg, sizeof (msg));
pid_filho = wait();
}
}A system call dup duplica um descritor de ficheiro de forma que:
- aponta para o mesmo ficheiro que descritor que está a ser duplicado;
- tem o mesmo modo de acesso que o tal descritor (leitura, escrita, leitura/escrita).
- o descritor de ficheiro returnado é o mais baixo disponível.
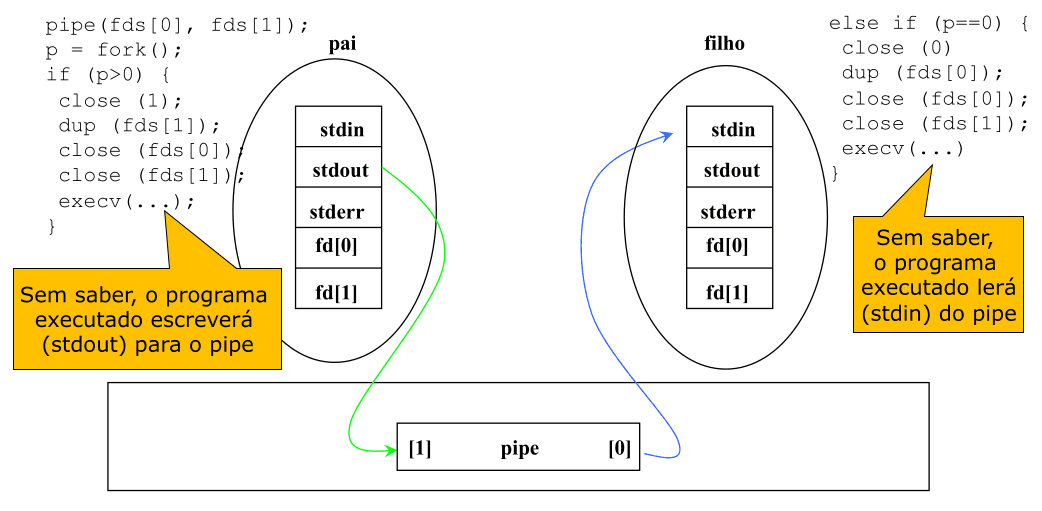
Exemplo: Redirecionamento de Entradas/Saídas
#include <stdio.h>
#include <fnctl.h>
#define TAMSG 100
char msg[] = "mensagem de teste";
char tmp[TAMSG];
main() {
int fds[2], pid_filho;
if (pipe(fds) < 0) exit(-1);
if (fork() == 0) {
/* processo filho */
/* liberta o stdin (posição zero) */
close(0);
/* redireciona o stdin para o pipe de
leitura */
dup(fds[0]);
/* fecha os descritores não usados pelo
filho */
close(fds[0]);
close(fds[1]);
/* lê do pipe */
read(0, tmp, sizeof (msg));
printf("%s\n", tmp);
exit(0);
}
else {
/* processo pai */
/* escreve no pipe */
write(fds[1], msg, sizeof (msg));
pid_filho = wait();
}
}É possível usar os pipes para redirecionar o input/output de programas na Shell.
Por exemplo, um comando como ls -la | grep xpto | ...etc... redireciona o output do comando ls -la para o input do comando seguinte - grep xpto - cujo output é de seguida também redirecionado para os comandos que seguem.
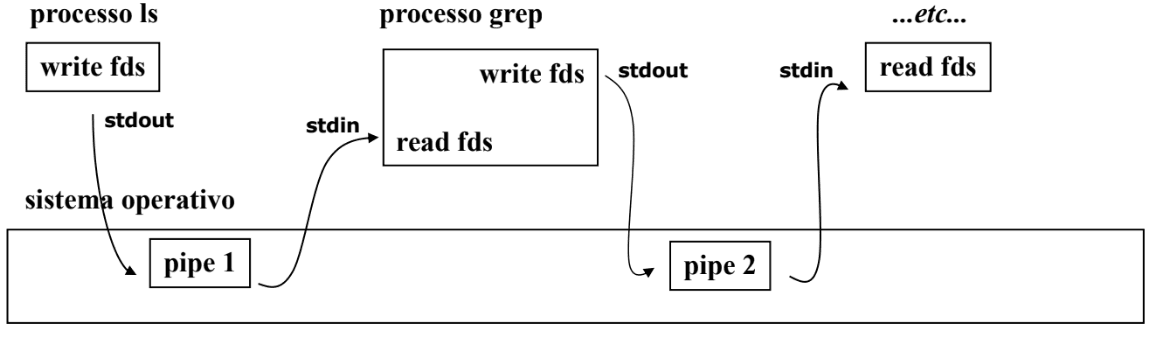
Exemplo: Redirecionamento de Entradas/Saídas
O comando indicado acima na shell podia ser implementado de forma semelhante à apresentada de seguida:
int main()
{
int fds[2]; int p;
pipe(fds);
p = fork();
if (p > 0){ // pai
close(1); dup(fds[1]);
execl("/bin/ls", "ls", "-la", 0);
}
else if (p == 0)
{
close(0); dup(fds[0]);
execl("/bin/grep", "grep", "xpto", 0);
}
return EXIT_FAILURE;
}Named Pipes ou FIFO
Para dois processos (que não sejam pai e filho) comunicarem é preciso que o pipe seja identificado por um nome.
Surgem então os named pipes: atribui-se um nome lógico ao pipe, usando o espaço de nomes do sistema de ficheiros.
Um named pipe comporta-se externamente como um ficheiro, existindo uma entrada na diretoria correspondente.
Estes podem ser abertos por processos que não têm qualquer relação hierárquica e tal como um ficheiro tem um dono e permissões de acesso.
Um named pipe então é um canal unidirecional (byte stream) identificado por um nome de ficheiro.
O named pipe existe entre os restantes ficheiros do sistema de ficheiros enquanto estiver aberto, não sendo, ao contrário dos restantes ficheiros, persistente.
Como Usar
- Criação dum named pipe no sistema de ficheiros:
mkfifo - Um processo associa-se a uma extremidade (leitura ou escrita) com a função
open, bloqueando até que pelo menos 1 processo tenha aberto a outra extremidade; - Eliminado dum named pipe do sistema de ficheiros:
unlink - Leitura e envio de informação feitos com API habitual do sistema de ficheiros (
read,write, etc)readbloqueia até que alguém escreva no pipe;writebloqueia até que alguém leia a mensagem escrita.
Exemplo com Named Pipes
/* Servidor */
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#define TAMMSG 1000
int main() {
int fcli, fserv, n;
char buf[TAMMSG];
/* Garantir que não há nenhum pipe associado a estes paths */
unlink("/tmp/servidor");
unlink("/tmp/cliente");
/* Criação dos pipes */
if (mkfifo("/tmp/servidor", 0777) < 0)
exit (1);
if (mkfifo("/tmp/cliente", 0777) < 0)
exit (1);
/* Abertura dos pipes */
if ((fserv = open("/tmp/servidor", O_RDONLY)) < 0)
exit(1);
if ((fcli = open("/tmp/cliente", O_WRONLY)) < 0)
exit(1);
for (;;) {
n = read(fserv, buf, TAMMSG);
if (n <= 0) break;
trataPedido(buf);
n = write(fcli, buf, TAMMSG);
}
/* Fechar e desassociar pipes */
close(fserv);
close(fcli);
unlink("/tmp/servidor");
unlink("/tmp/cliente");
return 0;
}
/* ------------------------------------------------------------ */
/* Cliente */
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#define TAMMSG 1000
void produzMsg(char *buf) {
strcpy(buf, "Mensagem de teste");
}
void trataMsg(buf) {
printf("Recebeu: %s\n", buf);
}
int main() {
int fcli, fserv;
char buf[TAMMSG];
/* Os pipes são criados e destruídos pelo servidor */
/* Abrir os pipes */
if ((fserv = open ("/tmp/servidor", O_WRONLY)) < 0)
exit(1);
if ((fcli = open ("/tmp/cliente", O_RDONLY)) < 0)
exit(1);
produzMsg(buf);
write(fserv, buf, TAMMSG);
read(fcli, buf, TAMMSG);
trataMsg(buf);
/* Fechar os pipes */
close(fserv);
close(fcli);
}Signals
Os signals têm dois propósitos distintos:
- Mecanismo usado pelo núcleo do SO para notificar um processo de que ocorreu um evento relevante (por exemplo:
CTRL-C, timeout, acesso inválido a memória, etc.); - Mecanismo limitado de comunicação entre processos - permite a um processo notificar outro que ocorreu um dado evento (por exemplo, processo servidor notifica outros processos para que iniciem procedimento de terminação); Em ambos os casos, o evento é tratado de forma assíncrona pelo processo.
Quando um processo é notificado do acontecimento de um evento assíncrono, deve reagir apropriadamente. Isto é feito através das rotinas assíncronas.
Rotinas assíncronas
Certos acontecimentos devem ser tratados pelas aplicações, embora não seja possível prever a sua ocorrência (por exemplo, Ctrl-C ou ações desencadeadas por um timeout).
Estes acontecimentos são tratados com Interrupções de Sistema.
RotinaAssincrona (Evento,Procedimento)
Para definir as rotinas assíncronas, tem de existir uma tabela com os eventos que o sistema pode tratar. Assim, para cada um destes eventos é feita a identificação do procedimento a executar assincronamente quando se manifesta o evento.
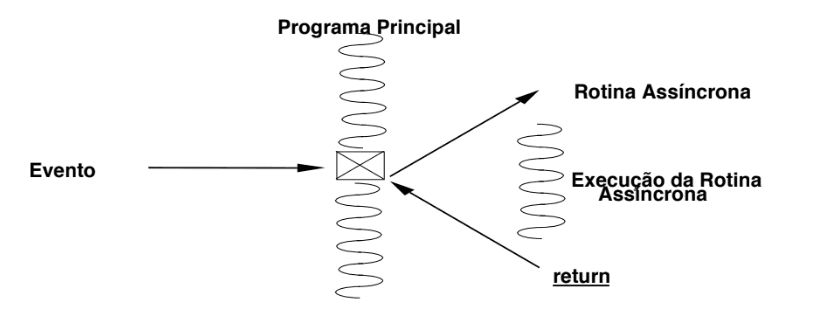
Os acontecimentos assíncronos em Unix estão definidos em signal.h. Cada um tem um tratamento por omissão que pode ser:
- Terminar o processo;
- Terminar o processo e criar ficheiro "core";
- Ignorar signal;
- Suspender o processo;
- Continuar o processo suspenso.
Funções sobre signals
Redefinir o Tratamento de um Signal
void (*signal (int sig, void (*func)(int))) (int)A função signal permite mudar o tratamento de um signal, tanto para outro tratamento pré-definido como para uma rotina específica do programa para tratar o signal.
O signal cujo tratamento é redefinido é passado no parâmetro int sig.
A nova rotina de tratamento do signal passada por void (*func)(int).
SIG_DFL- ação por omissão;SIG_IGN- ignorar o signal. A função retorna um ponteiro para função anteriormente associada aosignal.
O signal SIGKILL não pode ser redefinido (deve haver uma forma garantida de terminar um processo).
Exemplo de redefinir o tratamento de um Signal
#include <stdio.h>
#include <signal.h>
#include <stdlib.h>
void apanhaCTRLC(int s) {
char ch;
printf("Quer de facto terminar a execucao?\n");
ch = getchar();
if (ch == 's') exit(0);
else {
printf("Entao vamos continuar\n");
signal(SIGINT, apanhaCTRLC);
// Em alguns OS, o tratamento do signal
// volta para o default depois de ser tratado,
// sendo assim é preciso chamar signal outra vez
}
}
int main() {
signal(SIGINT, apanhaCTRLC);
printf("Associou uma rotina ao signal SIGINT\n");
for (;;)
sleep(10);
}Mandar signals
Para enviar um signal a um processo podemos usar:
int kill (pid_t pid, int sig);(em que pid é o identificador do processo e sig o do signal).
Se o pid for zero é enviado a todos os processos do grupo.
O envio de signals para processos de outro user está restrito ao superuser.
Outras funções associadas aos signals
unsigned alarm (unsigned int segundos)O signal SIGALRM é enviado para o processo depois de decorrerem o número de segundos especificados. Se o argumento for zero, o envio é cancelado.
int pause(void)Aguarda a chegada de um signal.
unsigned sleep (unsigned int segundos)A função chama alarm e bloqueia-se à espera do signal.
int raise(int sig)O signal especificado em input é enviado para o próprio processo.
Mais sobre Signals
Diferentes semânticas
Existem diferentes semânticas sobre signals. Nomeadamente Unix System V e Unix BSD:
Na semântica System V a associação de uma rotina a um signal é apenas efetiva para uma ativação. Depois de receber o signal, o tratamento passa a ser novamente o por omissão,sendo necessário associar de novo o tratamento que queremos (se quisermos que esse se mantenha). Entre o lançamento de rotina de tratamento e a nova associação -> tratamento por omissão pelo que é preciso restabelecer a associação na primeira linha da rotina de tratamento. Isto pode causar problemas se houver receção sucessiva de signals.
Na semântica BSD (e nas versões de Linux mais recentes, desde glibc2) a associação signal-rotina não é desfeita após ativação e a receção de um novo signal é inibida durante a execução da rotina de tratamento.
Boas práticas
Para ter código portável, é aconselhável não associar signals a rotinas que não SIG_DFL ou SIG_IGN.
Deve-se ainda usar a função sigaction (ver detalhes nas man pages).
Em plataformas Linux, para ter a certeza de obter semântica BSD, deve-se usar bsd_signal.
Funções async-signal-safe
-
A lista das funções que podem ser chamadas a partir dum signal pode ser obtida na página de manual do signal
-
Estas funções são também chamadas
async-signal-safee incluem:- funções reentrantes
- funções cuja execução não pode ser interrompida por signals (pois os bloqueiam durante a própria execução)
Quando um processo com múltiplas tarefas recebe um signal associado a uma função de tratamento, o OS escolhe por omissão uma tarefa do processo para ser interrompida e lidar com o signal.
É possível usar a função pthread_sigmask para impor que determinadas tarefas não tratem aquele signal. Se quisermos bloquear o signal basta cada tarefa chamar pthread_sigmask.
Matéria Fora de Avaliação
Existem nos slides matéria que para os mais curiosos pode ser interessante
Slides: