Gestão de Memória
Gestor de Memória
Definimos espaço de endereçamento de um processo como o conjunto de posições de memória que este pode referenciar.
Mais uma vez, é a função do SO oferecer ao utilizador uma interface que lhe permita aceder indiretamente à memória, de forma segura.
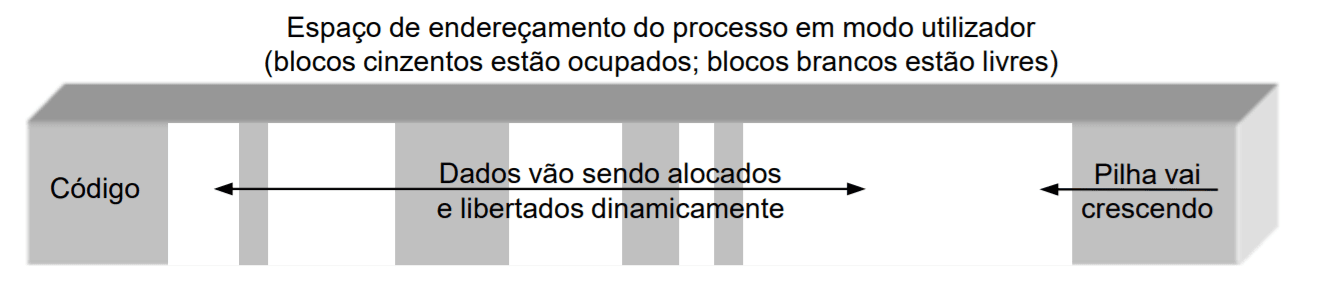
O gestor de memória deve também ter em consideração que a memória é constituída por:
-
Memória Principal (física ou primária):
- tempo de acesso reduzido;
- bom desempenho com acessos aleatórios;
- custo elevado;
- reduzida dimensão;
- informação volátil;
- RAM + caches [ + registos ].
-
Memórias secundárias (ou de disco)
- tempo de acesso elevado;
- pior desempenho com acessos aleatórios (entre blocos diferentes);
- custo reduzido;
- mais abundante;
- informação persistente.
O gestor de memória tem então a responsabilidade de gerir o espaço de endereçamento dos processos de forma que:
- assegurar que cada processo dispõe da memória que precisa;
- garantir que cada processo só acede à memória a que tem direito;
- otimizar desempenho dos acessos.
Endereçamento Virtual
Os endereços referenciados por um processo não correspondem diretamente ao espaços em memória onde a informação está guardada.
Os computadores têm um pedaço de hardware a que se dá o nome de unidade de gestão de memória (UGM) que estabelece um filtro que converte os endereços virtuais em endereços reais.
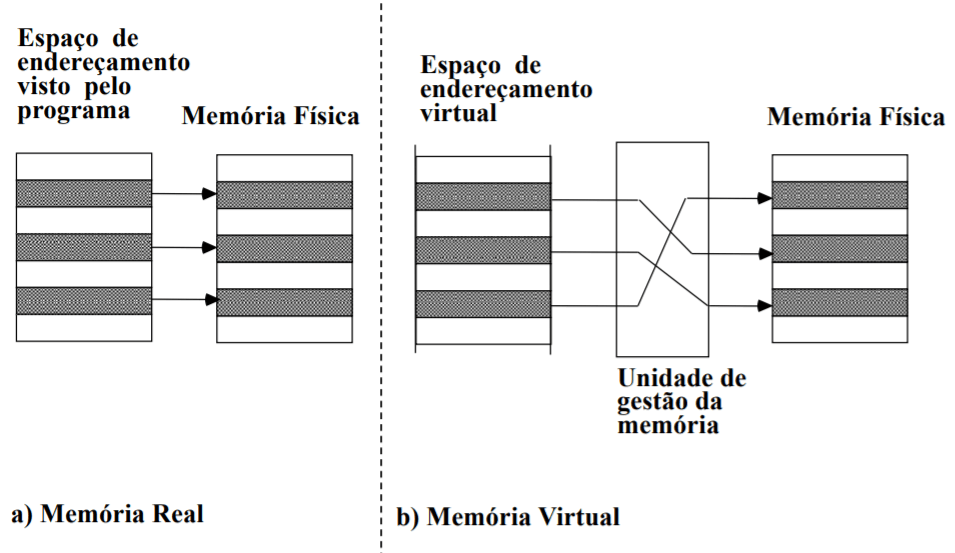
Para minimizar a informação necessária à conversão, a memória virtual é logicamente dividida em blocos contíguos.
Um endereço virtual corresponde então a um par (bloco, deslocamento).
Como vamos ver mais à frente há dois tipos de blocos: segmentos (dimensão variável) e páginas (dimensão constante).
A maioria dos acessos a memória são traduzidos e servidos pela UGM, sendo que um processo em modo utilizador mantém-se nesse modo. O núcleo só se envolve na tradução quando:
- comuta para outro processo;
- a página acedida não está presente (vamos ver mais à frente);
- acesso é ilegal (fora dos limites ou sem permissões)
Um bom gestor de memória deve evitar fragmentação:
- interna: desperdício de memória dentro de um bloco;
- externa: desperdício de memória entre blocos.
Segmentos
A segmentação consiste na divisão dos programas em segmentos lógicos que refletem a sua estrutura funcional (rotinas, módulos, código, dados, pilha, etc).
Assim, a conversão de endereços virtuais é linear em cada segmento, sendo o segmento a unidade de proteção e de carregamento em memória. Desta forma, a dimensão dos segmentos fica limitada: não pode exceder a dimensão da memória principal.
Nesta solução, o programador pode ter que se preocupar com a gestão de memória quando escreve um programa.
Os endereços físicos são obtidos pela UGM como descrito na imagem abaixo:
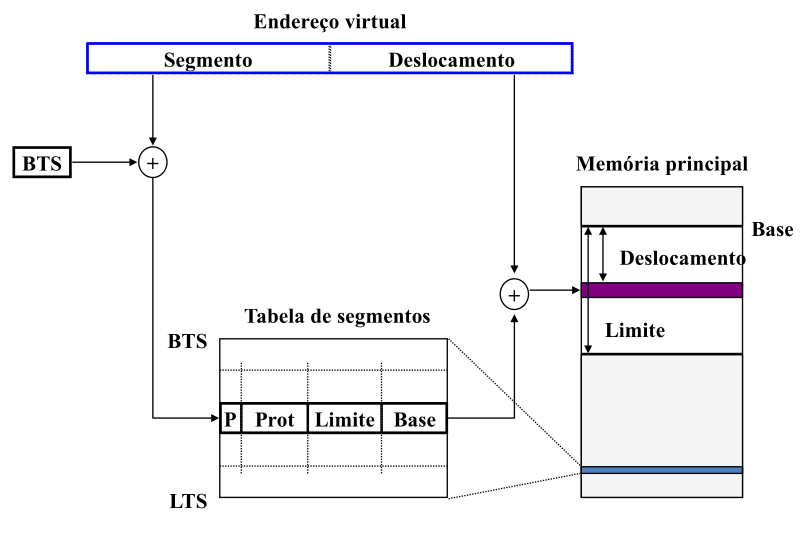
Como dito atrás, um endereço virtual é um par (segmento, deslocamento). Informação sobre os segmentos pode ser encontrada numa tabela de segmentos.
Através do segmento no endereço virtual, encontramos a posição nesta tabela em que se encontra a informação relativa a este segmento.
Uma entrada da tabela de segmentos é constituída por:
- bit P, que indica se o segmento correspondente a esta entrada está presente na memória principal;
- bits Prot que definem as proteções do segmento em causa, nomeadamente se o processo tem permissão para ler nele, escrever nele e/ou executá-lo.
- Limite, que indica o número de endereços que constituem este segmento. Desta forma, podemos verificar se estamos a aceder fora do endereço comparando o deslocamento com o Limite;
- Base, que corresponde ao endereço na memória principal em que está a informação relativa ao segmento.
Nota
A posição na tabela de segmentos correspondente a um segmento é obtida somando à posição do segmento o valor de BTS - Base da Tabela de Segmentos, um valor que corresponde à posição em memória em que a tabela de segmentos está guardada.
Este valor, bem como o LTS - Limite da Tabela de Segmentos, é guardado num registo da UGM, sendo mudado sempre que o CPU é atribuído a um processo novo.
O LTS serve para garantir que nenhum acesso a este segmento é feito fora do seu limite.
Páginas
A paginação consiste em constituir a memória por blocos de tamanho fixo, chamados páginas.

Em sistemas paginados, um endereço virtual será então um par (página, deslocamento) em que página define uma entrada na tabela de páginas.
Uma entrada da tabela de páginas é constituída por:
- bit P, que indica se a página correspondente a esta entrada está presente na memória principal;
- bits R e M que vamos ver mais à frente para que servem;
- bits Prot que definem as proteções da página em causa, nomeadamente se o processo tem permissão para ler nele, escrever nele e/ou executá-lo.
- Base, que corresponde ao endereço na memória principal em que está a informação relativa à página.
Nesta solução, os segmentos lógicos do espaço de endereçamento passam a ser compostos por múltiplas páginas, sendo possível um segmento lógico estar parcialmente presente. Se uma instrução do processador aceder a endereços em mais que uma página, a instrução pode encontrar uma falta de página a meio da execução. Desta forma, as instruções do processador têm de ser recomeçáveis.
Nesta solução, é relevante discutir qual a melhor dimensão para as páginas. Esta deverá ter em conta que influencia:
- a fragmentação interna;
- o número de faltas de páginas;
- tempo de transferência de páginas;
- a dimensão das tabelas de páginas e listas de páginas mantidas pelo sistema operativo.
Hoje em dia, o valor típico para o tamanho de páginas é 4 KBytes.
Nota
O facto de este valor ser uma potência de base 2 garante que o deslocamento de um dado endereço num bloco corresponde aos dígitos menos significativos do endereço real associado. Desta forma, a nível de arquitetura, a operação de obtenção do endereço real (base + deslocamento) pode ser feita com uma disjunção lógica (como aludido na imagem acima).
Otimização de Tradução de Endereços
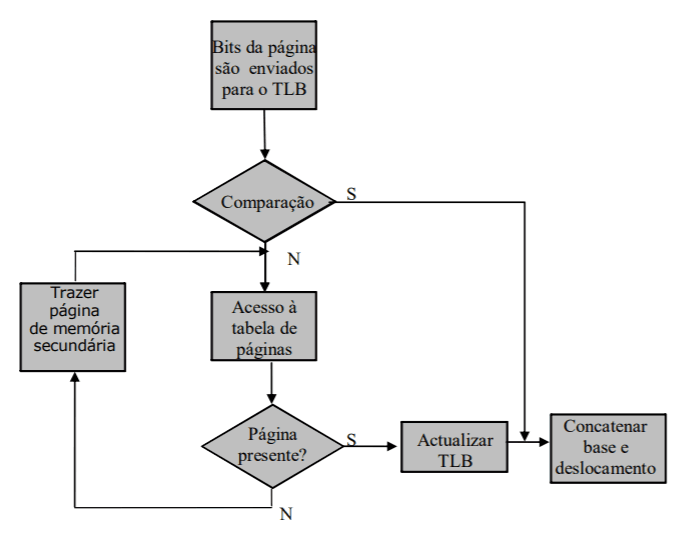
Para tornar o acesso a páginas o mais rápido possível, a UGM guarda uma tabela de tradução de endereços ou TLB (translation lookaside buffer). Esta tabela permite acesso bastante mais rápido às páginas pois está guardada em hardware, tal como a UGM.

A ideia é que as próximas páginas a que um programa aceda estejam nesta tabela. Como é impossível prever isso, mais uma vez, a UGM usa o princípio da localidade de referência. Desta forma, sempre que uma página é visitada, a UGM coloca a hipótese que esta página poderá voltar a ser requisitada num futuro próxima, pelo que coloca a sua posição em memória no TLB.
A dimensão desta tabela é pequena, em geral (64, 128 entradas), uma vez que o seu custo é elevado. A sua dimensão é testada de forma a obter percentagens de sucesso muito elevadas (90-95%).
Um fator que também influencia a dimensão da TLB é o quantum dos processos. A TLB é limpa em cada comutação de processos pelo que quanto maior for o quantum, maior é o número de páginas acedidas, o que leva à necessidade de ter mais entradas na TLB.
O carregamento das páginas na TLB é feito de acordo com o seguinte diagrama:
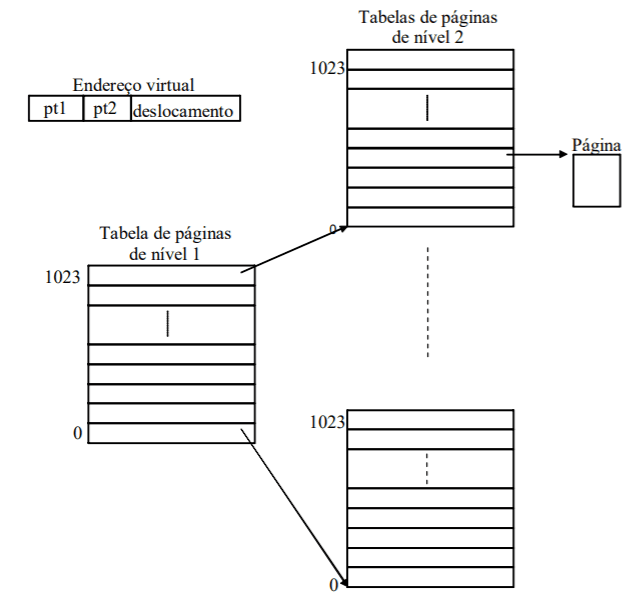
Tabelas de Páginas Multi-Nível
Assumindo que o espaço de endereçamento virtual tem endereços de 64 bits e páginas de 4 Kbytes ( bytes), temos que o espaço de endereçamento virtual consegue guardar páginas. Se uma entrada na tabela de páginas ocupar 4 bytes, temos que a tabela de páginas terá então bytes, ou seja 16 Petabytes.
Ora, isto é muita memória. Note-se que, sempre que um processo novo é iniciado, o SO precisa de aceder à tabela de páginas desse processo (nem que seja para ler na secção de código que instrução deve executar a seguir).
Ora, carregar 16 Petabytes para a memória principal é impossível.
É então necessária uma forma de endereçar as páginas sem consumir tanta memória.
É usada uma tabela de páginas multi-nível.
Existe uma tabela de páginas de nível 1, que endereça páginas que, elas próprias, consistem em tabelas de páginas.
Esta solução resolve o problema apresentado, garantindo que só estão em memória tabelas de páginas correspondentes às páginas que estão de facto a ser utilizadas pelo processo.
Partilha de Memória entre Processos
Para partilhar memória entre processos, basta ter, nas tabelas de páginas dos processos em causa, entradas com a mesma base. Os blocos (virtuais) partilhados não precisam de ser mapeados nos mesmos endereços virtuais em ambos os processos.
Partilhando memória entre processos, conseguimos ser mais eficientes a criar processos novos. Note-se que o fork() duplica o contexto de um processo pai. No entanto, não é feita nenhuma cópia física de memória no momento do fork. As páginas só são copiadas se e quando for necessário. Isto acontece se e só se algum dos segmentos de memória (do pai ou do filho) for alterado. Nesse caso, então, a memória é copiada e o bloco relevante é alterado para registar a alteração. A esta noção dá-se o nome de copy on write (CoW). Quando ocorre um fork() o gestor de memória:
- aloca uma nova tabela de páginas para o processo filho e copia o conteúdo da tabela do pai;
- nas entradas da tabela (tanto da do filho como da do pai) com permissão de escrita (dados e pilha), retira permissão de escrita e ativa bit CoW;
- quando o pai ou o filho tentam escrever numa página partilhada por CoW, ocorre uma exceção (pois não há permissão de escrita). Então, o núcleo acorda e:
- aloca uma nova página, para onde copia o conteúdo da página partilhada;
- atualiza a entrada da tabela do processo onde ocorreu a exceção com a base (endereço físico) da nova página e novas permissões (escrita ativada, CoW desativado);
- caso a página original já só seja referenciada por um processo, atualiza a entrada na tabela de páginas que lhe corresponde, atualizando as permissões (escrita ativada, CoW desativado). Caso contrário, as permissões mantêm-se.
Algoritmos de Gestão de Memória
Como já sabemos, a memória principal é escassa pelo que temos de a gerir eficazmente. Isto implica tomar decisões em relação aos conteúdos que lá são guardados, nomeadamente decisões de:
- Alocação: onde colocar um bloco na memória primária;
- Transferência: quando transferir um bloco de memória secundária para memória primária e vice-versa;
- Substituição: qual o bloco a retirar da memória.
Vamos estudar algoritmos que tratam estas três situações.
Alocação
Alocar memória em sistemas com paginação é muito simples: basta encontrar uma página livre, o que normalmente pode ser feito consultando uma lista de páginas livres guardada pelo SO.
Para segmentação, o tamanho variável dos segmentos torna mais complexa a reserva de espaço para um segmento. Na libertação de memória é necessário recompactar os segmentos.
Para a reserva de segmentos, podemos usar vários critérios de escolha:
-
best-fit (o menor possível):
- gera elevado número de fragmentos;
- em média percorre-se metade da lista de blocos livres na procura (com lista ordenada por tamanho);
- a lista tem de ser percorrida para introduzir o fragmento.
-
worst-fit (o maior possível):
- pode facilmente impossibilitar a reserva de blocos de grandes dimensões;
- a lista de blocos livres tem de ser percorrida para introduzir o fragmento.
-
first-fit (o primeiro possível):
- minimiza tempo gasto a percorrer a lista de blocos livres;
- gera muita fragmentação externa;
- acumula muitos blocos pequenos no início da lista, ficando para o fim os blocos maiores.
-
next-fit (o primeiro possível, a seguir à pesquisa anterior):
- espalha os blocos pequenos por toda a memória.
Transferência
Há três abordagens para a transferência de segmentos:
- a pedido (on request): o programa ou o sistema operativo determinam quando se deve carregar o bloco em memória principal;
- por necessidade (on demand): o bloco é acedido e gera-se uma falta (de segmento ou de página), sendo necessário carregá-lo para a memória principal;
- por antecipação (prefetching): o bloco é carregado na memória principal pelo sistema operativo porque este considera fortemente provável que ele venha a ser acedido nos próximos instantes. Isto é normalmente feito de acordo com o princípio da localidade de referência.
Transferência de Segmentos
A transferência de segmentos faz-se usualmente a pedido.
Normalmente, para executar um processo são necessários em memória pelo menos um segmento de código, de dados e de stack.
Caso haja escassez de memória, os segmentos de outros processos que não estejam em execução são transferidos na íntegra para disco (swapping).
Os segmentos são guardados numa zona separada do disco chamada área de transferência (swap area).
Quando são transferidos todos os segmentos de um processo diz-se que o processo foi transferido para disco (swapped out).
Nota
Em arquiteturas que suportem a falta de segmentos, certos segmentos de um programa podem ser transferidos para memória principal por necessidade.
Transferência de Páginas
O mecanismo normal de transferência de páginas é por necessidade. Desta forma, páginas de um programa que não sejam acedidas durante a execução de um processo não chegam a ser carregadas em memória principal.
Usam-se ainda políticas de transferência por antecipação para diminuir o número de faltas de páginas e otimizar os acessos a disco.
Quando é necessário libertar espaço na memória física, o SO copia páginas para disco, guardando-as na área de paginação ou swap area.
As páginas que vão para disco são aquelas que o SO prevê que não serão acedidas num futuro próximo.
Estas são transferidas em grupos para memória secundária de modo a otimizar os acessos a disco.
Neste contexto, estabelecemos uma diferença entre swapping - guardar todas as páginas de um processo em disco - e paging - guardar páginas individuais em disco.
Área de Paginação vs Swap Area
Historicamente, a expressão "swap area" está mais frequentemente associada a sistemas com segmentos.
Por seu lado, "paging area" diz respeito a sistemas baseados em paginação.
No entanto, a expressão "swap area" é tão comum que também é muito usada em sistemas paginados.
Possíveis critérios para decidir qual o processo a transferir para disco:
- estado e prioridade do processo: processos bloqueados e pouco prioritários são candidatos preferenciais;
- tempo de permanência na memória principal: um processo tem que permanecer um determinado tempo a executar-se antes de ser novamente enviado para disco;
- dimensão do processo.
Definimos o espaço de trabalho de um processo como o conjunto de páginas acedidas pelo mesmo num intervalo de tempo. O espaço de trabalho de um processo tende a ter dimensão constante e muito menor que o seu espaço de endereçamento. Se o SO estimar essa dimensão, pode evitar colocar o processo em execução enquanto não existirem suficientes páginas disponíveis em RAM.
Substituição
Analisaremos apenas soluções de substituição para sistemas com paginação.
A heurística para o algoritmo de substituição ótimo é que devemos (mais uma vez) retirar a página cujo próximo pedido seja mais distante no tempo. Para estimar isto, vamos medir o uso recente das páginas. Para isto podemos usar vários sistemas:
FIFO:
- associar a cada entrada da tabela de páginas um timestamp de quando esta foi colocada em RAM;
- tirar a entrada que está em RAM há mais tempo;
Este sistema é muito eficiente mas não atende ao grau de utilização das páginas.
Sistema NRU (Not Recently Used):
- em cada entrada da tabela de páginas são mantidos bits R e M;
- a UGM coloca R=1 quando há leitura na página e M=1 quando há escrita;
- o paginador percorre regularmente as tabelas de páginas e coloca o bit R a 0;
- obtemos assim 4 grupos de páginas:
- 0 (R = 0, M = 0): Não referenciada, não modificada;
- 1 (R = 0, M = 1): Não referenciada, modificada;
- 2 (R = 1, M = 0): Referenciada, não modificada;
- 3 (R = 1, M = 1): Referenciada, modificada;
- libertam-se primeiro as páginas dos grupos de número mais baixo.
Sistema LRU (Least Recently Used):
É eficaz segundo o princípio de localidade de referência, tendo uma latência rigorosa associada à sua implementação.
O algoritmo é aproximadamente o seguinte:
- em cada entrada na tabela de páginas é mantido um bit R e um valor de Idade;
- o paginador faz uma ronda regular pelas páginas, aumentando a idade daquelas com o bit R a 0;
- sempre que uma página é acedida (leitura ou escrita), a UGM coloca R=1 e a sua idade é anulada;
- quando uma página atinge uma idade determinada, esta passa para a lista de páginas que podem ser transferidas.
Comparação entre Paginação e Segmentação
Segmentação
Vantagens:
- adapta-se à estrutura lógica dos programas;
- permite a realização de sistemas simples sobre hardware simples;
- permite realizar eficientemente as operações que agem sobre segmentos inteiros.
Desvantagens:
- o programador tem de ter sempre algum conhecimento dos segmentos subjacentes;
- os algoritmos tornam-se bastante complicados em sistemas mais sofisticados;
- o tempo de transferência de segmentos em memória principal e disco torna-se incomportável para segmentos muito grandes;
- a dimensão máxima dos segmentos é limitada.
Paginação
Vantagens:
- o programador não tem que se preocupar com a gestão de memória;
- os algoritmos de reserva, substituição e transferência são mais simples e eficientes;
- o tempo de leitura de uma página de disco é razoavelmente pequeno;
- a dimensão dos programas é virtualmente ilimitada.
Desvantagens:
- o hardware é mais complexo que o de memória segmentada (por exemplo, instruções precisam de ser recomeçáveis);
- operações sobre segmentos lógicos são mais complexos e menos elegantes, pois têm de ser realizadas sobre um conjunto de páginas;
- o tratamento das faltas de páginas representa uma sobrecarga adicional de processamento;
- tamanho potencial das tabelas de páginas.
Gestão de Memória em Unix/Linux
Unix
As primeiras implementações de Unix (até versão 7) executavam-se com arquitetura segmentada de 16 bits, com espaços de endereçamento de 64 Kbytes, dividido em oito segmentos de 8 Kbytes cada. A gestão de memória era muito simples:
- os processos eram carregados na sua totalidade em memória;
- caso não houvesse espaço disponível em memória, o SO transferia para memória secundária os processos que estivessem bloqueados ou com menor prioridade;
- a transferência de processos era feita por um processo denominado swapper.
As versões atuais de Unix usam principalmente arquiteturas paginadas e dividem o espaço de endereçamento em três regiões: código, dados e pilha. Novas regiões podem ser criadas dinamicamente durante a execução dos programas. Cada região tem uma tabela de páginas própria.
A substituição de páginas usa uma aproximação ao algoritmo LRU. A idade da página é mantida na entrada da tabela de páginas correspondente. O page-stealer é acordado quando o número de páginas livers desce abaixo de um dado limite, marcando para ser transferida as páginas que atingem uma certa idade.
Linux
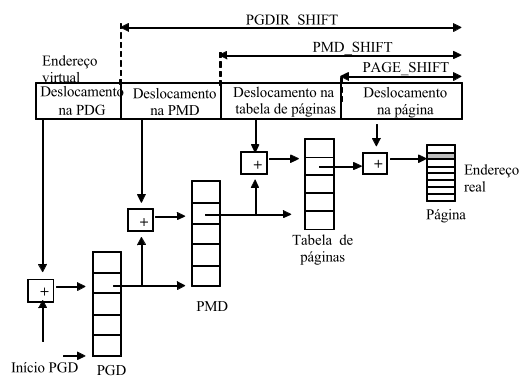
Linux usa tabelas de páginas multinível com três níveis:
- Page Global Directory (PGD): tabela de mais alto nível;
- Page Middle Directory (PMD): tabela de nível intermédio;
- Tabela de páginas;
Os endereços virtuais neste sistema são então constituídos por quatro secções: uma secção que determina a posição na tabela em cada um dos três níveis e uma secção que determina o deslocamento na página.
Informação Incompleta
Nesta secção falta informação sobre a tabela de páginas em Linux - a tabela pfdata