Everything is a File
Ficheiro
Toda a gente sabe o que é um ficheiro, mas definir um exatamente pode ser algo mais difícil.
Definimos um ficheiro como uma coleção de dados persistentes, geralmente relacionados, identificados por um nome.
Os vários ficheiros de um certo sistema estão normalmente organizados num sistema de ficheiros.
Um sistema de ficheiros deve ser composto por um conjunto de entidades fundamentais:
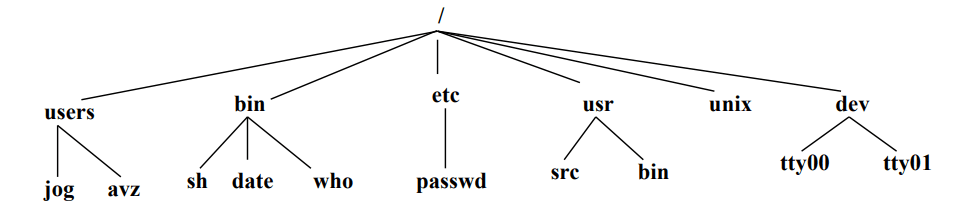
- um sistema de organização de nomes para identificação (humana) dos ficheiros (normalmente hierárquico);
- meta-informação sobre cada ficheiro que deve:
- estar no mesmo sistema de memória secundária que a informação que descreve;
- entre outros, estabelecer a associação entre o nome (identificador para os humanos) e um identificador numérico (para o computador);
- uma interface programática para comunicação entre os processos.
Ao executar o comando ls numa consola Linux podemos ver os ficheiros que se encontram numa diretoria.
Se usarmos a flag -l, associada a cada ficheiro vem a sua meta-informação:
-rwxr-xr-x 1 luis staff 8680 Nov 14 19:46 do_exec
Eis a informação que está apresentada na linha acima (por ordem):
- permissões do ficheiro:
-rwxr-xr-x- podem ser de leitura (
r), escrita (w) e execução (x); - o que o primeiro dos dez caracteres significa não é do âmbito desta cadeira;
- os seguintes 9 caracteres dividem-se em 3 conjuntos - cada um representa as permissões de uma certa entidade. Nomeadamente, por esta ordem: user, group e others;
- neste caso, a mensagem apresentada diz-nos que:
- o utilizador do ficheiro tem todas as permissões sobre aquele ficheiro;
- os restantes utilizadores do grupo têm permissões de escrita e execução, mas não de escrita;
- qualquer outro utilizador também só pode ler ou executar;
- podem ser de leitura (
- o número de hard links que existem para este ficheiro (vamos ver melhor o que isto significa mais à frente):
1; - o nome do
utilizadorque é dono do ficheiro:luis; - o nome do
grupoque é dono do ficheiro:staff; - o tamanho do ficheiro:
8680(bytes); - a data e hora da última modificação do ficheiro:
Nov 14 19:46; - o nome do ficheiro:
do_exec.
Vamos começar por aprender a usar os sistemas de ficheiros (abstrações, APIs).
Everything is a File
O Unix usa uma filosofia de organização de dados onde tanto pastas como ficheiros serão tratados da mesma forma. Esta é chamada a filosofia "Everything is a file". Segundo esta filosofia:
- Os objetos que o SO gere são acessíveis aos processos através de descritores de ficheiro, como por exemplo ficheiros, diretorias, dispositivos lógicos, canais de comunicação, etc;
- Isto permite que os utilizadores e programadores tenham um modelo de programação e de segurança comum para todos os objetos do SO;
Nomes Absolutos e Nomes Relativos
Para aceder a um ficheiro temos de saber como referir ao SO a qual ficheiro estamos a querer aceder.
Temos assim 2 maneiras de o fazer:
- Nomes Absolutos:
- Caminho de acesso desde a raiz (root, normalmente denominado
/) - Exemplo:
/home/joao/SO/project.zip
- Caminho de acesso desde a raiz (root, normalmente denominado
- Nomes Relativos:
- Caminho de acesso a partir do diretório corrente
- O diretório corrente é mantido para cada processo como parte do seu contexto
- Exemplos:
./SO/project.zip(supondo que o diretório corrente é/home/joao)../SO/project.zip(supondo que o diretório corrente seja/home/joao/teo)
Links
Um ficheiro pode ser conhecido por vários nomes, ou seja, é possível querermos associar um dado conjunto de dados a mais que um nome (eventualmente em diretorias diferentes). Por exemplo, é possível designar o mesmo ficheiro com o nome /a/b/c e com o nome /x/y. É comum chamar a cada um destes nomes links (em Unix, chama-se hard links).
No entanto, isto levanta um problema: o que acontece quando se pretende apagar o ficheiro com o nome /a/b/c?
A semântica utilizada na maioria dos sistemas de ficheiros é apagar apenas o nome /a/b/c
e deixar o ficheiro se ainda tiver mais nomes associados.
Mounting
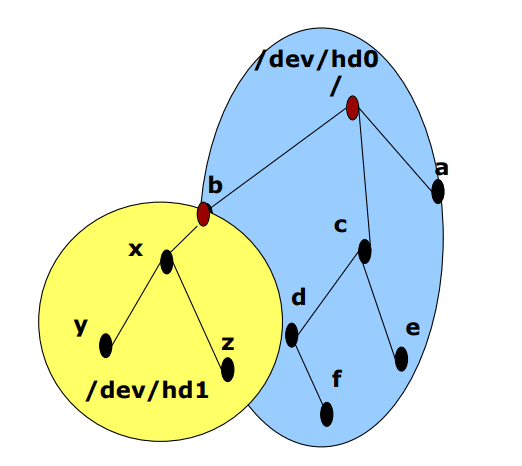
Por vezes podemos querer organizar múltiplos sistemas de ficheiros. Em Unix isto pode ser feito através do comando:
mount -t <filesystem> /dev/hd1 /bO comando mount liga a raiz do novo sistema de ficheiros a um diretório do sistema de ficheiros base.
Na figura acima, liga /dev/hd1 ao diretório /b.
Programar com Ficheiros
As operações mais frequentes sobre ficheiros são a leitura e escrita. No entanto, para que seja possível fazermos estas operações precisamos de ser capazes também de abrir e fechar um ficheiro, por exemplo.
Operações Básicas sobre Ficheiros
Processo: é a instância de um programa em execução.
- É mantida uma Tabela de Ficheiros Abertos por processo
- Para abrir um ficheiro é necessário:
- Pesquisar o diretório e verificar que o ficheiro existe;
- Verificar se o processo tem permissões para o modo de acesso que está a ser pedido;
- Copiar a meta-informação para memória (incluindo o modo de acesso solicitado)
- Devolver ao utilizador um identificador que é usado como referência para essa posição de memória
- Ler e escrever sobre ficheiros abertos:
- Dado o identificador de ficheiro aberto, conseguimos obter rapidamente o descritor do ficheiro em memória;
- Fechar do ficheiro:
- Liberta a memória que continha a meta-informação do ficheiro
- Caso necessário, atualiza essa informação no sistema de memória secundária
Primitivas do Sistema de Ficheiros
Podemos dividir as funções relacionadas com o sistema de ficheiros em seis grupos:
- Abertura, criação e fecho de ficheiros
- Operações sobre ficheiros abertos
- Operações complexas sobre ficheiros
- Operações sobre diretórios
- Acesso a ficheiros mapeados em memória (Não vai ser dado a SO)
- Operações de gestão dos sistemas de ficheiros.
Abertura, Criação e Fecho de Ficheiros
| Retorno | Nome | Parâmetros | Descrição |
|---|---|---|---|
fd := |
Abrir | (Nome, Modo) | Abre um ficheiro |
fd := |
Criar | (Nome, Proteção) | Cria um novo ficheiro |
| Fechar | (fd) |
Fecha um ficheiro |
Na tabela acima, fd simboliza o file descriptor.
Operações sobre Ficheiros Abertos
| Nome | Parâmetros | Descrição |
|---|---|---|
| Ler | (fd, buffer, bytes) |
Lê de um ficheiro para um buffer de memória |
| Escrever | (fd, buffer, bytes) |
Escreve um buffer para um ficheiro |
| Posicionar | (fd, posição) |
Posiciona o cursor de leitura ou escrita |
Operações Complexas sobre Ficheiros
Algumas operações sobre ficheiros permitem realizar operações sobre a totalidade do ficheiro, como copiá-lo, apagá-lo ou movê-lo.
| Nome | Parâmetros | Descrição |
|---|---|---|
| Copiar | (Origem, Destino) | Copia um ficheiro |
| Mover | (Origem, Destino) | Move um ficheiro de um diretório para outro |
| Apagar | (Nome) | Apaga um ficheiro |
| LerAtributos | (Nome, Tampão) | Lê atributos de um ficheiro |
| EscreverAtributos | (Nome, Atributos) | Modifica os atributos |
Na tabela acima, memória tampão significa buffer.
Operações sobre Diretórios
| Nome | Parâmetros | Descrição |
|---|---|---|
| ListaDir | (Nome, Tampão) | Lê o conteúdo de um diretório |
| MudaDir | (Nome) | Muda o diretório por omissão (diretório atual) |
| CriaDir | (Nome, Proteção) | Cria um novo diretório |
Canais Standard
Inicialmente, quando um processo é iniciado, a sua tabela de ficheiros é preenchida com 3 ficheiros abertos:
stdin(standard input)stdout(standard output)stderr(standard error)
Normalmente, estes ficheiros referenciam os canais de input e output da consola em que o processo foi lançado.
No entanto, estes canais podem ser alterados, podendo também receber e enviar para ficheiros:
foo < out.txt # redireciona o conteúdo de out.txt para o stdin de foo
ls > listagem.txt # redireciona o stdout de foo para listagem.txt
foo >& erros.txt # redireciona o stderr para o mesmo local que o stdoutAPI do Sistema de Ficheiros
Abrir Ficheiro
Até este momento fizemos sempre leituras do stdin e escrevemos sempre para o stdout. Vamos ver agora como realizar estas operações sobre ficheiros.
FILE *fp; // Ponteiro para estrutura que representa o ficheiro aberto
fp = fopen("tests.txt", "r"); // Modo de abertura do ficheiro.
// Neste caso estamos a abrir o ficheiro
// em modo de leitura.r- abre para leitura (read)w- abre um ficheiro vazio para escrita (o ficheiro não precisa de existir)a- abre para acrescentar no fim (“append” ; ficheiro não precisa de existir)r+- abre para escrita e leitura; começa no início; o ficheiro tem de existirw+- abre para escrita e leitura (tal como o “w” ignora qualquer ficheiro que exista com o mesmo nome, criando um novo ficheiro)a+- abre para escrita e leitura (output é sempre colocado no fim)
Existem outros tipos de abertura, mas estes são os principais.
Exemplos
#include <stdio.h>
#include <stdlib.h>
int main()
{
FILE *fp;
fp = fopen("teste.txt", "r"); // Se não conseguir abrir,
// fp fica igual a NULL
if (fp == NULL) {
printf("teste.txt: No such file or directory\n");
exit(1);
}
return 0;
}#include <stdio.h>
#include <stdlib.h>
int main()
{
FILE *fp;
fp = fopen("teste.txt", "r");
if (fp == NULL) {
// Escreve a mesma mensagem de erro.
// perror() escreve no "standard error" (stderr)
// a descrição do último erro encontrado na chamada a
// um sistema ou biblioteca.
perror("teste.txt");
exit(1);
}
return 0;
}#include <stdio.h>
#include <stdlib.h>
int main()
{
FILE *fp;
fp = fopen("teste.txt", "r");
if (fp == NULL) {
perror("teste.txt");
exit(1);
}
fclose(fp); // Fecha o ficheiro
return 0;
}#include <stdio.h>
#include <stdlib.h>
int main()
{
FILE *fp;
// Permite escrever para um ficheiro
fp = fopen("teste.txt", "w");
if (fp == NULL) {
perror("teste.txt");
exit(1);
}
fprintf(fp, "Hi file!\n"); // Escreve para o ficheiro
fclose(fp); // Fecha o ficheiro
return 0;
}#include <stdio.h>
#include <stdlib.h>
int main()
{
FILE *fp;
fp = fopen("teste.txt", "w");
if (fp == NULL) {
perror("teste.txt");
exit(1);
}
fputs("Hi file!", fp); // Escreve para um ficheiro (alternativa)
fclose(fp);
return 0;
}A função fputs muda de linha após escrever no ficheiro (adiciona \n),
mas não permite usar strings formatadas (e.g. %s, %d, etc) como o fprintf.
#include <stdio.h>
#include <stdlib.h>
int main()
{
FILE *myfile; int i;
float mydata[100];
myfile = fopen("info.dat", "r"); // Permite ler o ficheiro
if (myfile == NULL) {
perror("info.dat");
exit(1);
}
// Lê um conjunto de 100 floats
for (i = 0; i < 100; i++)
fscanf(myfile, "%f", &mydata[i]); // guardados num ficheiro
fclose(myfile);
return 0;
}#include <stdio.h>
#include <stdlib.h>
int main()
{
FILE *myfile;
int i;
// Permite adicionar ao final do ficheiro
myfile = fopen("info.dat", "a");
for (i = 0; i < 100; i++)
fprintf(myfile, "%d\n", i);
fclose(myfile);
return 0;
}O Cursor
- Para qualquer ficheiro aberto, é mantido um cursor, isto é, em que local do ficheiro estamos.
O cursor avança automaticamente com cada byte lido ou escrito. - Para sabermos em que posição estamos, podemos usar função
ftell:long ftell(FILE *stream); - Para repor o cursor noutra posição, podemos usar a função
fseek.int fseek(FILE *stream, long offset, int whence);- O argumento
offsetindica quantos bytes queremos andar para frente (positivo) ou para trás (negativo), relativo ao argumento que passamos parawhence. - O argumento
whencerecebe uma das constantesSEEK_SET,SEEK_CURouSEEK_END, que indica se ooffseté relativo ao início dastream, à posição atual ou ao final dastream, respetivamente.
- O argumento
Persistência de Escritas
Após escrita em ficheiro, essa escrita está garantidamente persistente no disco? Nem sempre!
Para otimizar o desempenho, escritas são propagadas para disco tardiamente, pelo que poderá não estar tudo guardado em disco quando a escrita termina.
A função fflush permite ao programa forçar que escritas feitas até agora sejam persistidas em disco:
- Função só retorna quando houver essa garantia
- No entanto, é uma função demorada, pelo que se deve usar apenas quando necessário
int fflush(FILE *stream);
API do Unix
Em vez de usarmos a biblioteca stdio, poderíamos utilizar diretamente
as funções da API do sistema de ficheiros do Unix.
Temos os seguintes prós e contras:
Prós:
- Em geral, são funções de mais baixo nível, logo permitem maior controlo
- Algumas operações sobre ficheiros só estão disponíveis através desta API
Contras:
- Normalmente, programa que usa
stdioé mais simples e otimizado

Slides: