Machine Learning
Para iniciarmos esta cadeira, temos que ter bem presentes alguns conceitos, sendo o mais significativo o conceito de Machine Learning.
O que é Machine Learning?
Aprender é um conceito fundamental quando quantificamos inteligência. Para o ser humano, aprender está na base de tudo pois ninguém nasce ensinado. O mesmo aplica-se a qualquer máquina, daí ter sido criado o conceito Machine Learning. Partindo da psicologia e biologia o principal objetivo desta área de estudo é mimicar o modelo de pensamento humano.
"Learning is any process by which a system improves performance from experience" - Herbert Simon
Mas como é que é possível pôr uma máquina a raciocinar como um ser humano? Bem, faz sentido começar com o conceito Inteligência Artificial, que, tal como já tinha sido referido na respetiva UC, afirma que todas as nossas ações têm várias componentes diferentes por detrás. Todo o nosso raciocínio, antes de realizarmos o que quer que seja, passa por três principais etapas (etapas essas que procuramos espelhar recorrendo a máquinas computacionais):
-
Razão: idealmente, procuramos ter uma justificação para a ação que estamos a realizar. A título de exemplo, ao fazermos uma jogada num jogo de xadrez, temos que saber porque é que estamos a mover a peça para um dado sítio, o porquê de o fazer e as consequências (positivas e negativas) que a jogada nos trará;
-
Adaptabilidade: tal como o ser humano, uma máquina tem que ser capaz de aprender com as suas ações, quer sejam positivas ou negativas. Voltando ao exemplo do jogo de xadrez, ao efetuarmos uma jogada conseguimos perceber os efeitos esperados (e não só) da mesma, conseguindo assim perceber se é uma boa jogada ou não, se há alternativas melhores, entre outros pormenores. Tal como vamos ver nesta UC, é também assim que as máquinas aprendem!
-
Criatividade: a criatividade nas máquinas tenta espelhar as emoções humanas, sendo uma área muito procurada atualmente. Pretendemos encontrar soluções de maior inteligência sem ser somente com base no raciocínio - queremos encontrar soluções mais "outside of the box", portanto. Um bom jogador de xadrez não joga sempre a "melhor jogada" (estatisticamente falando), procurando também efetuar jogadas que surpreendam o adversário.
Sistemas
Podemos agora orientar as atenções para a parte de adaptabilidade - tal como sabemos, corresponde a uma sub-área da Inteligência Artificial que pode ser registada através de um sistema ao longo do tempo, ou até por múltiplos sistemas registados juntamente com observações de experiência. Podemos, daqui, extrair que sempre que pretendemos aprender precisamos de um sistema: isto é, precisamos de um conjunto de elementos, organizados com um objetivo em comum, influenciado pelo seu meio (caso seja aberto, claro). Um sistema é descrito pela sua estrutura, objetivo e função.
Estes sistemas estão em todo o lado, e podem ser sistemas:
- Biológicos;
- Ecológicos;
- Societários;
- Mecânicos;
- Digitais;
- Quantum;
- Híbridos;
- Astrofísicos;
- Urbanos;
- Entre muitos outros!
É através destes sistemas, tal como já foi referido acima, que as nossas máquinas aprendem: as máquinas observam o sistema (e todas os objetos que ele habitam), registando todo um leque de tipos de dados, procurando assim, recorrendo à experiência, aprender mais sobre o sistema e extrair dele a informação que pretende! Esta aprendizagem ou reconhecimento de dados é o que nos ajuda a perceber o comportamento de um determinado sistema (descriptive learning) e apoia decisões e recomendações futuras (predictive learning).
Machine Learning e Data Science são dois termos particularmente em voga recentemente. Procuremos distingui-los:
| Machine Learning | Data Science |
|---|---|
| Serve para melhorar as decisões tomadas a partir dos dados adquiridos | Serve para descobrir o que não sabemos a partir dos dados adquiridos |
| Conjunto de conceitos, princípios e métodos computacionais | Extração não trivial de conhecimentos implícitos, importantes e anteriormente não sabidos |
| Parte de estatística, álgebra, matemática e algoritmos | Parte de Machine Learning |
Olhando agora para a distinção entre Machine Learning e a área da Inteligência Artificial, a principal diferença está nos inputs e outputs dos respetivos programas: em inteligência artificial, são dados como input um conjunto de dados e uma função de heurística, sendo retornada uma jogada/caminho/classificação/etc. Em Machine Learning, o "output" de IA é precisamente um dos inputs (a par dos dados): os modelos procurarão aprender a partir do que lhes é fornecido, procurando assim retornar um programa/modelo inteligente, capaz de fazer classificações/previsões corretas.
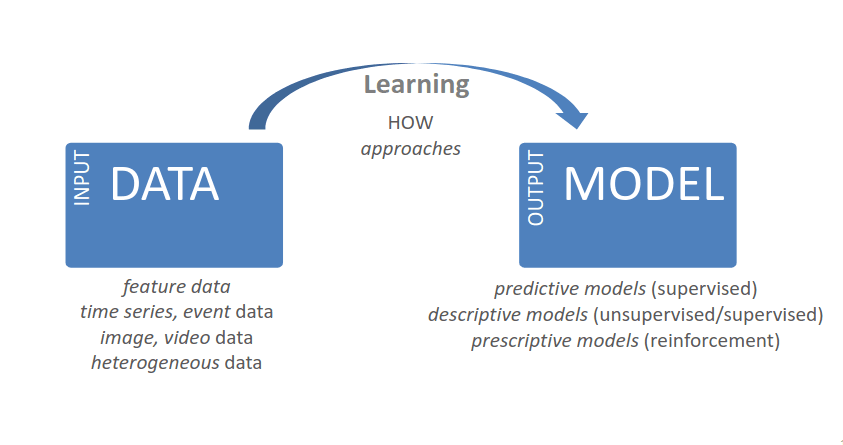

Aprendizagem
Contudo, de que forma é que estas máquinas podem aprender? Bem, existem três principais formas:
- Aprendizagem supervisionada: com um professor ou através de dados de treino e outputs desejados, isto é, etiquetas, quantidades ou estruturas;
- Aprendizagem não supervisionada: sem um professor e através de dados de treino sem outputs desejados, procura-se "agrupar" os dados em diferentes categorias, conseguindo assim receber uma dada instância e dizer "esta instância deve pertencer àquela categoria";
- Aprendizagem por reforço: sem um professor designado para dar exemplos negativos ou positivos, através de prémios e penalidades observadas através da sequência de ações dentro de um ambiente específico.
O processo de aprendizagem também se caracteriza por ser feito em diferentes etapas.
A primeira etapa, pré-processamento de dados, refere-se a aquisição de
dados, integração e limpeza dos mesmos: isto é, deteção de outliers,
normalização dos dados, redução de dimensão, entre outros tratamentos.
De seguida, passamos à etapa de mineração de dados, recorrente em Machine Learning.
Aqui, procura-se observar um dataset, encontrando associações locais ou padrões
que satisfaçam critérios estatísticos significativos (número mínimo de observações de
modo a contrariar expectativas, para remoção de outliers), e poder discriminatório
de alvos qualitativos ou correlação entre critérios.
Por fim, temos uma fase de pós-processamento de dados,
que serve para extrair a informação e conhecimento (descriptive stance) assim
como os modelos aprendidos (predictive stance), podendo desta forma interpretar
e validar os resultados e consolidar os conhecimentos descobertos.
Symbolic Learning
Dentro das várias vertentes existentes em Machine Learning, uma das principais é Symbolic Learning. Popular entre 1970 e 1990, esta área de estudo refere-se principalmente a como símbolos são construções criadas pela mente humana, de modo a simplificar a resolução de problemas, que, posteriormente, são usados para nos referirmos a várias partes do mundo. O sistema aprende uma representação simbólica através da análise de exemplos positivos e negativos de um conceito. O nome parte precisamente da noção associada à informação ser apresentada através de símbolos.
Statistical Machine Learning
A segunda vertente mais relevante é statistical machine learning, contendo conceitos como regressões lineares, clustering e redes neuronais. Estes dois tipos de Machine Learning diferem principalmente no método através do qual a informação é apresentada: através de símbolos e vetores, respetivamente.
Ao contrário da vertente anterior, esta abordagem opta por representar os objetos diretamente. Análogo à biologia, onde os órgãos percetores capturam informação através de recetores, optamos por criar vetores, onde cada dimensão representa um certo valor. Podemos também pensar nas várias dimensões como atributos. Por exemplo, podemos comparar dois peixes pelos seus peso e tamanho. Ao representar objetos desta maneira podemos comparar duas entidades medindo a distância euclidiana entre os dois vetores que a representam. O processo de escolher os atributos a representar chama-se extração de atributos.
O objetivo poderá ser, então, discriminar os peixes em dois conjuntos, consoante as dimensões analisadas. Vários algoritmos de Machine Learning realizam esta divisão, de maneiras diferentes. O algoritmo Perceptron tenta determinar a linha que separa os dois tipos de peixes, neste exemplo.
Estes algoritmos operam sobre uma amostra estatística. Ao utilizá-lo para classificar um outro peixe, não há garantias de que a classificação seja de facto correta, problema conhecido como overfitting. Este pode ser também resultado de outliers estatísticos, em que, por exemplo, um salmão pode ter atributos muito semelhantes a um peixe de outra espécie, distorcendo a linha de separação entre as duas espécies. Este fenómeno ocorre devido a uma pequena amostra de treino.
Uma amostra reduzida não é representativa da população. Uma solução poderia ser aumentar esta amostra, mas muitas vezes é impossível. Faz-se então um compromisso, dando espaço a um pequeno erro. Este compromisso é descrito pelo pressuposto de que a curva de distinção terá de ser suave, de acordo com a teoria da regularização.
Espaços destacados
Aprender através de uma base de dados é obter relações de dados relevantes, estas relações são padrões ou abstrações que equivalem a distribuições de interesse em observações específicas e atributos que podem ser inesperadamente informativos ou inesperadamente discriminativos.
Quando as nossas variáveis visualizadas são numéricas, um espaço destacado representa um vetor espaço, por exemplo o espaço de Euclides, e as observações representam pontos dos dados.